Table of Contents
Our Global Presence :
Home / Blog / AI/ML
What is Deep Learning? A Beginner’s Guide for Business Leaders
by
March 26, 2025

by
March 26, 2025
If you’re a modern business leader looking to propel your business further by leveraging emerging technologies, the first thing you need to do is understand them. Deep learning is one such emerging technology your competitors have been using recently to give themselves an edge.
So, what is deep learning?
Read along with us as we dive into deep learning basics, its common types, and a brief description of how it works. In addition, we also discuss some best practices for training deep learning models and some popular deep learning applications in the modern day.
Let’s go!
What is Deep Learning?
Deep learning is a branch of machine learning that mimics the human brain. It uses multilayered artificial neural networks (deep neural networks) to learn from data and simulate humans’ complex decision-making process. Without any explicit instructions, deep learning systems can recognise and learn patterns from large amounts of data, automatically improve over time, and handle some specialised tasks.
The following are some common examples of tasks that you can perform with the help of deep learning systems.
- Image recognition
- Natural language processing
- Speech recognition
- Item classification
As a result, you can use deep learning to automate unique tasks that would normally require human intelligence.
How does Deep Learning Work?
Deep learning works by gleaning insights using neural networks. When the system receives new data, it can make accurate predictions and recognise, classify, and describe based on these insights.
So, what are these “deep learning neural networks?”
These are several layers of interconnected nodes that work together to solve complex problems. You can think of them as the artificial versions of the millions of biological neurons that function together in the human brain. However, these artificial nodes use complex mathematical calculations to process data.
A deep neural network has three major components, namely:
- Input Layer:
The nodes at this layer are responsible for processing data and ingesting it into the deep learning system.
- Hidden Layer:
The nodes at this layer are responsible for processing the information fed into the system. Let’s say the model is for speech recognition and classification, and different examples of speech data have been fed into the system at the input layer. The hidden layer tries to analyse this data from different angles to make an accurate classification.
Deep learning models may have hundreds of hidden layers, each trying to process different features that will help the system become more accurate over time. After the hidden layer finishes processing the data, it passes it further down to the next layer.
- Output Layer
The nodes at this layer are responsible for making the final prediction or classification based on the analyses of the hidden layer.
In a deep learning model, you’ll notice that data and computations progress gradually from one layer to another throughout the network. This progression is called forward propagation.
When the network does this continuously, it gradually starts learning and gets better with time. During this iterative process, the weights on the connections between the nodes are gradually adjusted so that the model can accurately classify the data, and this optimisation process is called training.
The training process uses algorithms such as gradient descent to estimate any prediction errors and adjust the weights accordingly. This process is known as backpropagation.
As such, deep learning works by using processes such as forward propagation to feed and process data through its three major components — input, hidden, and output layers — while using backpropagation and training to adjust its weights at every iteration.
But how does this compare to machine learning?
Let’s find out below as we explore the key differences and similarities between deep learning and machine learning.
Explore our AI Development Success Stories
Over the years, we’ve helped businesses like yours implement effective deep-learning solutions that moved their businesses forward.
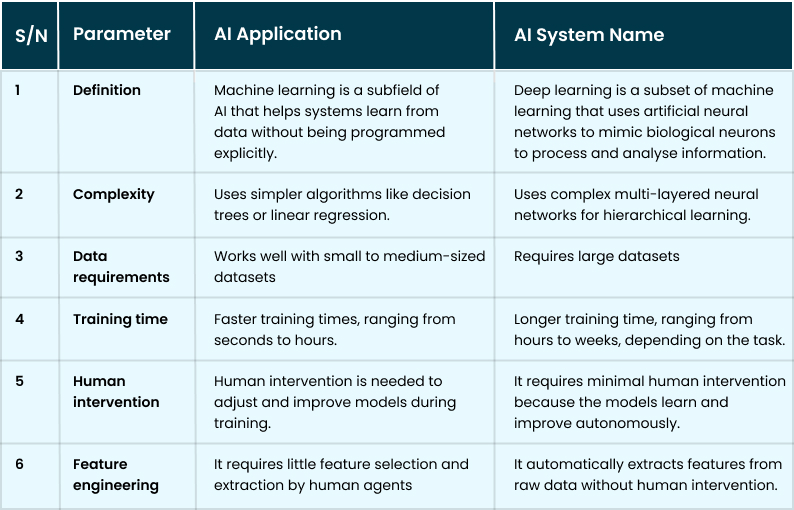
Deep Learning vs Machine Learning: Key Differences and Similarities
Put simply, deep learning (DL) is a subfield of machine learning (ML), which, in turn, is a subfield of artificial intelligence (AI).
Many people use both terms interchangeably and understandably, as both machine learning and deep learning are really cool ways to teach computer systems and machines what to do. More so, machine learning consulting firms like Debut Infotech Pvt Ltd offer both services side by side.
Nonetheless, some subtle differences exist between them.
But first, let’s examine the similarities between `them.
Similarities Between Machine Learning and Deep Learning
The following are the similarities between machine learning and deep learning:
- Both concepts are forms of artificial intelligence.
- Both machine learning and deep learning learn from data to make predictions, classifications, or perform other specialised tasks.
- Both approaches apply mathematical computations and models to glean insights from data.
- They both handle complex tasks.
- Unlike traditional programming, which requires explicit instructions from developers and engineers, machine learning and deep learning improve automatically with time by practising with more data.
Now, let’s look at the differences between these terms.
Differences Between Machine Learning and Deep Learning
The table below summarises the differences between machine learning and deep learning.
Types of Deep Learning Models
The following are some of the common types of deep learning models being applied across different systems today:
1. Feedforward Neural Networks (FNNs)
Feedforward neural networks (FNNs) are deep learning models in which information flows only forward—from the input layer through the hidden layer to the output layer. As such, this type of deep learning model does not have cycles or loops.
FNNs are among the simplest and earliest deep learning models ever devised. They are also known as deep networks, multilayer perceptrons (MLPs), or neural networks.
2. Convoluted Neural Networks (CNNs)
Convoluted neural networks (CNNs) are unique types of deep learning models that activate the nodes in the network when the output of such individual nodes exceeds the threshold. They use convolutional layers to detect spatial hierarchies, making them particularly good for tasks like object detection, image recognition, and face recognition.
Even when the objects in an image appear obscured or distorted, CNNs can identify them properly because they have multiple hidden layers that focus on individual distinct features of the image.
3. Recurrent Neural Networks (RNNs)
RNNs are deep learning models that are more adept at natural language processing and speech recognition due to their preference for sequential or time-series data. Their recurrent nature implies that they use feedback loops. As such, they use their “memory” to influence newer inputs and outputs.
They are primarily applied in use cases such as stock market predictions, sales forecasting, language translation, natural language processing, etc.
4. Deep Reinforcement Learning (DRLs)
As the name implies, deep reinforcement learning (DRL) combines two powerful techniques—deep learning and reinforcement learning—to create a model that learns sophisticated strategies for extracting complex features from unstructured data. DRL teaches an agent how to behave by correcting its actions after a series of trial-and-error and “punishments.”
As such, they are particularly useful for robotics and gaming purposes.
5. Generative Adversarial Networks (GANs)
GNNs are a special type of deep learning model comprising two different networks—a generator and a descriptor—that compete to improve the network’s overall accuracy. These models create new data that resembles the original training data and can be used to train the machine learning model further.
The name “adversarial” in this model depicts the back-and-forth nature of the entire network between the generator and the descriptor.
6. Transformer Models
Transformer models are a type of deep learning architecture capable of processing input sequences in parallel, thus requiring less training time than RNNs and CNNs. These models introduce two major innovations into the context of prediction: positional encoding and self-attention.
These innovations have enabled transformer models to translate text and speech in near real-time. For instance, OpenAI’s chatGPT text generation tools use this transformer architecture model to answer questions, summarise texts, and make predictions.
7. Diffusion Models
Diffusion models are generative deep learning models that produce new data similar to what they have been trained on. They “diffuse” samples with random noise and reverse the diffusion process to produce high-quality outputs like images. Recently, OpenAI used diffusion models in DALL-E-2, its image generation tool.
Based on their mode of image generation, diffusion models can generate data simply by passing randomly sampled noise through the learned reversed diffusion or denoising process.
Other notable examples of deep learning models include autoencoders and variational autoencoders, with more models being actively developed daily. For businesses like yours looking to leverage the capabilities of deep learning models, following the best practices for training them could help you get the best possible value.
Let’s examine them in the following section.
Best Practices for Training Deep Learning Models
Following the best practices listed below can help you build and train a deep learning model that performs excellently in real-world situations.
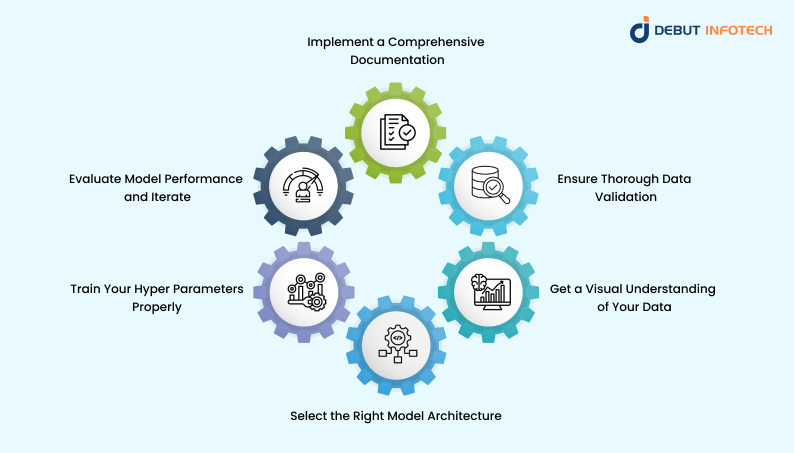
1. Implement a Comprehensive Documentation
Maintaining comprehensive documentation means keeping accurate records of your model’s design, assumptions, number of features, and even meticulous details of all adjustments made during the training process. Doing this helps you understand, optimise, and maintain the model over a longer period.
Not only that.
Comprehensive documentation also helps ensure continuous development and troubleshooting when multiple personnel are working on the same model. The documented details show anyone working on the model its structure and logic for continuous optimisation.
2. Ensure Thorough Data Validation
A thorough data validation ensures that your model is trained with only high-quality data, which improves its performance.
You can ensure thorough data validation by screening your raw data for issues like corrupted files, inconsistencies, missing entries, and basically anything that would make the dataset unfit for training. Once you find them, implement comprehensive data cleaning operations like eliminating problematic entries. Likewise, you should also maintain data consistency by making sure your data follows a uniform format.
3. Get a Visual Understanding of Your Data
Data visualisation helps you get better results from your model training efforts by showing you hidden patterns and potential issues that could inform your model training process. Therefore, it is advisable to explore the relationships and trends hidden in the raw data using plots and charts. You can also check out visualisation tools like correlation heatmaps, which help you predict the features that are more closely related to the outcome you’re probing.
Data visualisation also helps you glean insights that will help you determine the right features to use for training.
4. Select the Right Model Architecture
Depending on the insights you glean from data visualisation, you should be able to identify the right deep-learning model for the dataset you have. You can choose anyone from RNNs and CNNs to diffusion models, GANs, and transformer models.
For more context, image recognition tasks are best tackled by CNNs, while RNNs are your best choices for sequences like text.
5. Train Your Hyper Parameters Properly
This process of training your hyperparameters is also known as hyperparameter tuning. It’s vital to ensure that your deep learning model learns accurately, avoids errors, and generalises properly to new data.
Hyperparameter tuning also helps you avoid overfitting and underfitting, save time and resources, and enhance model performance.
6. Evaluate Model Performance and Iterate
Deep learning model training is an iterative process. So, you must constantly monitor the model’s performance on the selected validation set. In response to the observed performance, the hyperparameters are constantly adjusted to ensure that the model is learning maximally. You can follow metrics like accuracy or loss to monitor how well the model is learning.
With the processes listed above and constant monitoring, you should be well on your way to training your deep-learning models for optimal performance.
Now, let’s check out some common examples of deep learning applications around us.
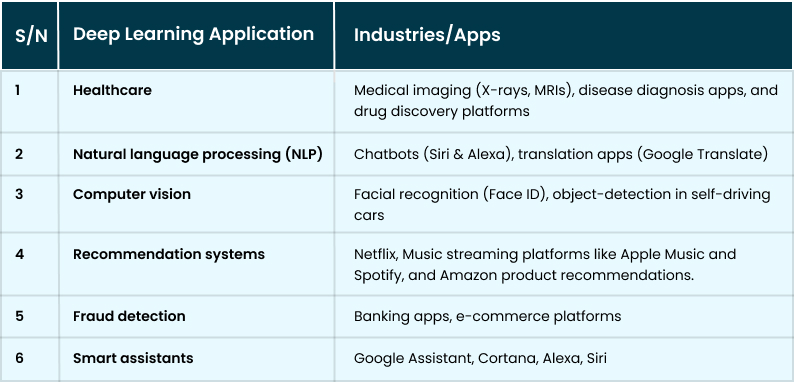
Examples of Common Deep Learning Applications
The table below highlights some common vital deep learning applications and the common industries or applications where you can find them in use:
Develop a Deep Learning-Powered Application that Strengthens Your Business
Deep learning models are strong enough to propel your business further, regardless of your industry.
Conclusion: Should you Invest in Deep Learning Models?
Yes, you should!
You’ve seen the awesome things this technology can do. Wouldn’t you like your business to benefit from them?
While it is understandable that the concepts might seem a bit abstract if you’re still a beginner, you can always trust an AI development company to understand your business needs and requirements and know which deep learning models are ideal for you.
Deep learning offers many advantages, whether you’re looking to build segregation systems, sophisticated computer vision systems, or high-tech fraud detection algorithms. Debut Infotech Pvt Ltd is the perfect place to get the right implementation.
Frequently Asked Questions (FAQs)
Q. Is chatGPT deep learning?
A. Yes, deep learning is the foundation of ChatGPT. It uses a deep neural network architecture known as the Generative Pre-trained Transformer (GPT), which uses self-attention processes and transformer networks. These allow it to process and produce human-like language by using deep learning techniques to find patterns in large datasets.
Q. Which software is used for deep learning?
A. Building and training deep learning models involve using software such as Tensorflow, PyTouch, Keras, Microsoft Cognitive Toolkit (CNTK), VisoSuite, Caffe, etc. These tools help in diverse areas, such as model development and training, research and production, and deployment.
Q. Who invented deep learning?
A. Over several decades, a number of researchers pioneered deep learning. Frank Rosenblatt (1958), who created the Perceptron, and Warren McCulloch and Walter Pitts (1943), who suggested artificial neurons, are examples of early contributors. Later advances in neural networks and training techniques were made by Geoffrey Hinton, Yann LeCun, and Jürgen Schmidhuber.
Q. What are the four pillars of deep learning?
A. Artificial Neural Networks (ANNs), backpropagation, activation functions, and gradient descent are four of the most vital pillars in deep learning technology.
Q. Can I learn deep learning on my own?
A. Although it requires a significant amount of sheer will, determination, and hard work, deep learning is something you can learn on your own. Start by enrolling in online courses. Next, use projects and tutorials to familiarise yourself with libraries like PyTorch and TensorFlow. For assistance and criticism, join groups like Reddit’s r/MachineLearning or Kaggle.
Talk With Our Expert
Our Latest Insights




USA
Debut Infotech Global Services LLC
2102 Linden LN, Palatine, IL 60067
+1-703-537-5009
[email protected]
UK
Debut Infotech Pvt Ltd
7 Pound Close, Yarnton, Oxfordshire, OX51QG
+44-770-304-0079
[email protected]
Canada
Debut Infotech Pvt Ltd
326 Parkvale Drive, Kitchener, ON N2R1Y7
+1-703-537-5009
[email protected]
INDIA
Debut Infotech Pvt Ltd
C-204, Ground floor, Industrial Area Phase 8B, Mohali, PB 160055
9888402396
[email protected]
Copyright © 2025, Debut Infotech. All rights reserved. | Privacy Policy
Leave a Comment