Table of Contents
Our Global Presence :
Home / Blog / AI/ML
Stable Diffusion: Rethinking Creativity and Business Automation
by
April 18, 2025

by
April 18, 2025
Stable Diffusion, a groundbreaking Generative AI model, is redefining creativity in various industries by helping businesses create exquisite graphics with just text or image prompts.
That’s right! You think of a visual representation you want, enter it into this model, and voila! It’s right there.
Imagine the awesome benefits this could have on your business. Not only does it accelerate your workflows, but it also empowers your business to deliver cutting-edge solutions. For executives seeking to stay ahead in this AI-driven era, understanding and integrating this technology could be the push you need for that competitive edge.
Don’t believe me?
How about you discover the awesome capabilities of stable diffusion models?
In this article, we discuss what stable diffusion is, how to use stable diffusion, and the components responsible for its awesome capabilities.
Let’s dive in!
What is Stable Diffusion?
Stable diffusion is a popular and open-sourced diffusion model for generating images with prompts. It is an extension originating from the Latent Diffusion Model (LDM), making it a text-to-image model
This latent generative AI model is equipped to produce unique photo-realistic images from both text and image prompts. As such, it empowers billions of people to generate art in just a few seconds. In addition to images, the model can also create videos and animations with the right prompts or text descriptions.
Here’s the cool part:
Any person with a desktop or laptop can run this model to create their preferred images. Diffusion models run on latent space using diffusion technology, so they have little processing requirements.
Care to learn how stable diffusion models transform text and image prompts into photo-realistic images?
Skip to the next section as we discuss the main architectural components of stable diffusion.
Integrate Stable Diffusion into Your Existing Processes for Business Growth
Your business process can become more efficient with the help of Stable Diffusion.
Components of the Stable Diffusion Model
The following are the architectural components of the stable diffusion model, all of which work together during both training and inference to generate the image.
- Pretrained text encoder
The pre-trained text encoder plays a crucial role during the stable diffusion model’s training and inference phases.
It helps convert the text prompt a user provides into embeddings. This is like converting the sentence or phrase into numerical representations so that the model captures the meaning and context of the word in the text.
By providing this meaning and context from the prompt, it also conditions the image generation process so that the stable diffusion model generates something very close to the image a user requests.
In simpler terms, it is safe to say that the pre-trained text encoder helps the stable diffusion model to understand what you want to see in the generated image based on your text prompt.
- A U-Net noise predictor
The stable diffusion model uses the U-Net noise predictor as a noise predictor and for denoising images.
Wondering what noise means in the context of a stable diffusion model?
Noise means random imperfections or distortions in the image. It’s the grainy spots or speckles that’ll make the picture look unclear — kind of like the unclear attributes you’ll find in a low-quality photo you’ve taken yourself.
So, the U-Net noise predictor helps the stable diffusion model to “clean up” the image and make it appear clearer.
You should know that U-Net noise predictors are convoluted neural networks
But, basically, the U-Net noise predictor’s role is to estimate the amount of noise in the latent space and deduct it from the generated image based on the user-specific steps.
- A variational autoencoder-decoder model
The variational autoencoder-decoder model comprises a separate encoder and decoder.
These parts have two major tasks: the encoder generates the latent space information by compressing the original 512 x 512 pixel image into a smaller 64 x 64 model (in the latent space).
On the other hand, the decoder predicts the image from the text-conditioned latent space and restores the 64 x 64 model in latent space into a full-size 512 x 512 pixel image
The variational autoencoder also contains an upsampler network for generating the final high-resolution image.
- Forward Diffusion
While Forward Diffusion is more of a process than an actual component, it is vital to Stable Diffusion’s image generation process.
The Forward Diffusion process is the gradual action of adding noise (majorly Gaussian noise) to an image over several steps till it fully becomes random noise.
“Wait, but the U-Net noise predictor is meant to remove noise.”
So, why is the Forward Diffusion process trying to add noise to it?
That’s because it helps train the model to reverse this process, which is crucial during the image generation process. The logic is that if the model learns how to add noise to an image, then it automatically knows how to remove it as well when the model needs to generate an image.
However, Forward Diffusion is no longer a common process across all Stable Diffusion models. Instead, it is used when performing image-to-image conversions.
- Reverse Diffusion
As you might have guessed, reverse diffusion is the opposite of forward diffusion.
It is a parameterized process of gradually removing the noise from a noisy image till you have a clear and meaningful image.
Feeling confused?
It’ll all make sense very soon. In the next section, we give some insights into how stable diffusion models work with these components and processes.
Read on!
How does Stable Diffusion Work?

The stable diffusion model combines all the components and individual processes discussed above to produce an image when you input a text prompt. The steps involved in the image generation process can be vividly described as follows:
1. Text Encoding
This is the first step after a user enters an image generation prompt into the stable diffusion model. The Pre-trained Text Encoder, which we talked about earlier, is typically a CLIP model. It converts the text prompt into a numerical format called embeddings. This conversion is necessary to ensure the model captures the prompt’s meaning and context, which will be important in the image generation process.
2. Image Compression
Stable diffusion doesn’t operate in high-dimensional image space. Rather, it first compresses the image into the latent space using the variational autoencoder, reducing the complexity of the image data. It’s important for the stable diffusion model to operate in this low-dimensional latent space so that the model can run easily and more efficienCTAtly on consumer-grade hardware.
3. Forward Diffusion Process
After image compression, the stable diffusion model gradually destroys the image by adding Gaussian noise until it completely becomes random noise. This process is crucial for training the model as it helps the model to learn how to reverse the noise addition, which is essential for image generation.
4. Reverse Diffusion Process
The Reverse Diffusion process can also be called Denoising. It is the reverse process of the Forward Diffusion process, as it involves gradually removing noise from the random image, step by step, until a clear image is formed. The U-Net noise predictor is responsible for this process. Furthermore, the text embeddings created earlier by the pre-trained text encoder are used to guide this process to ensure the generated image matches the text prompt.
5. Text Conditioning
Text conditioning is the process responsible for integrating the embeddings into the denoising or image generation process. It uses a technique known as cross-attention. This ensures that the generated image aligns with the text prompt. Text conditioning allows users to control what appears in the generated image by specifying details in the text prompt.
6. Image Reconstruction
Once the noise is removed and the image is clear in latent space, the variational autoencoder-decoder model regenerates or reconstructs the image from scratch to its original size and resolution. This final step produces a high-quality image that matches the user’s text prompt.
What Can Stable Diffusion do?
Using the components and different combinations of the processes described above, the Stable Diffusion model can be used to perform a variety of tasks. Most of these tasks have major applications in fields like marketing, product design, and creative content generation
Some of them include the following:
- Text-to-image Generation: This is perhaps the most obvious and common application of the Stable Diffusion model. The model can generate a unique image based on a user’s prompt.
- Image-to-image Generation: The stable diffusion model can also create an image based on another image and a text prompt. For instance, you may create a sketch and provide specific instructions on how stable diffusion can either complete that sketch or use it as an inspiration for its image output.
- Video Creation: Stable Diffusion can also be used to create short video clips and animations using features like Deforum from Github. This application has some vital variations, like adding artistic styles to movies and animating photos.
- Image Editing and Retouching: Just like with video creation, stable diffusion can also be used to edit and make slight adjustments to an existing image. The model has editing features like the AI editor and the eraser brush, which can be used to mask specific areas in an image. Of course, you have to input contextual prompts detailing the kinds of edits you wish to make.
- Creation of Graphics, Artworks, and Logos: Stable Diffusion can also leverage advanced deep learning techniques to generate visual representations of logos, artworks, and graphics that match brand identities. Like the other generation processes, this application is based on select prompts. Users can also guide the generation process using a sketch.
These five are some of the most common ways users make use of the stable diffusion models.
However, there are quite a number of other diffusion models capable of performing these functions.
So, how does stable diffusion differ from these options?
We talk about this in the next section.
What is the Difference Between Stable Diffusion and Other Text-to-Image Diffusion Models?
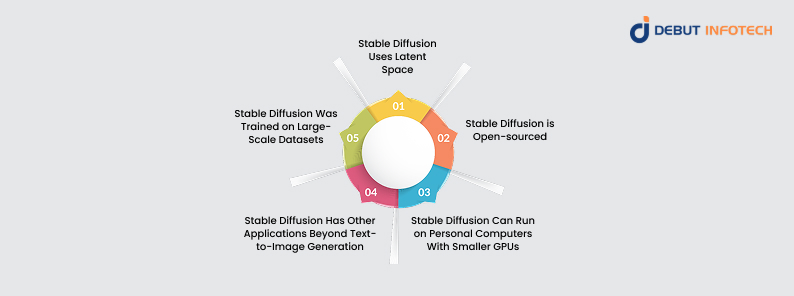
Although their outputs may share some similarities, stable diffusion differs from other text-to-image diffusion models in the following regards:
1. Stable Diffusion Uses Latent Space
Most other examples of text-to-image diffusion models like the DALL-E (versions 1 and 2) by OpenAI use the image’s pixel space. Stable Diffusion differs in this regard because it uses the compressed latent space instead.
For example, it compresses a 512 x 512 resolution image into 64 x 64 latent space dimensions to reduce the process’s computational requirements while maintaining high-quality outputs.
2. Stable Diffusion is Open-sourced
Because it is open-source under the Creative ML OpenRAIL-M license, users can freely access, modify, and redistribute the stable diffusion model for both commercial and non-commercial purposes. Other text-to-image diffusion models, on the other hand, are proprietary, like the DALL-E, which is owned by OpenAI.
3. Stable Diffusion Can Run on Personal Computers With Smaller GPUs
Due to its use of latent space instead of pixel space, the stable diffusion model can run on personal computers with GPUs as small as 4 GB VRAM. In contrast, other models like DALL-E require more computational resources and are even primarily accessible via cloud-based services.
Imagen is another diffusion model by Google Research that also uses the Pixel Space. Due to its high computational resource requirements, it’s not even designed for local use or consumer-grade hardware.
4. Stable Diffusion Has Other Applications Beyond Text-to-Image Generation
As we highlighted earlier, stable diffusion can be used for a variety of other purposes, such as image-to-image generation, image editing and retouching, video creation, etc. Other text-to-image diffusion models are usually built specially for text-to-image generation, as they have limited secondary features.
Furthermore, stable diffusion can also add or replace parts of the image due to auxiliary functionalities like inpainting and outpainting.
5. Stable Diffusion Was Trained on Large-Scale Datasets
While other text-to-image diffusion models use proprietary datasets for training their models, stable diffusion was trained using three datasets collected by LAION through the common crawl. These include the LAION- Aesthetics v2.6 dataset of images, which has an aesthetic rating of 6 or higher.
How to Use Stable Diffusion
Ready to generate images using stable diffusion?
You can do this primarily through two major ways, namely:
- Using an API on your local machine
- Through an online software program
If you decide to run it through your local machine, you need to ensure your device specs match the model’s computation resource requirements.
Once you have these requirements, you need only input a descriptive and contextual prompt that clearly expresses the kind of image you aim to create, and Stable Diffusion will do the rest.
Create Tailored Generative AI Solutions for Your Business
Leverage our expansive Generative AI development expertise to create solutions powered by Stable Diffusion models.
Conclusion
Stable Diffusion is not just a tool for creative expression. Rather, it is a strategic—and free—asset for businesses that want to innovate and differentiate themselves quickly.
Think about it:
Faster design processes, clearer and more coherent brand materials, and new revenue streams. Those are the possible benefits your business could reap with this groundbreaking technology.
However, while the model’s open-source nature makes it free, you still need strategic planning and strong expertise to integrate such advanced technology into your existing workflows and processes. This is where partnering with a seasoned Generative AI development company can make all the difference.
Here at Debut Infotech Pvt Ltd, our team specializes in helping businesses like yours build tailored AI solutions that drive growth, efficiency, and innovation.
Partner with us today to transform your business with the power of AI.
Frequently Asked Questions (FAQs)
Q. Can I use Stable Diffusion for free?
Yes, you can use Stable Diffusion for free because it is an open-source model. You can run it locally on consumer-grade computers or via cloud-based platforms like Google Colab. Furthermore, tools like Automatic111’s Web UI guarantee free access to the model without you needing to install it.
Q. What are the minimum PC requirements for Stable Diffusion?
For Stable Diffusion, a PC must have at least 12GB of storage space, preferably on an SSD, a GPU with at least 4GB of VRAM, and a Windows, MacOS, or Linux operating system. For improved performance, it is advised to have at least 16GB of RAM.
Q. What is the difference between Stable Diffusion and Midjourney?
While Midjourney is a cloud-based application that can be accessed through Discord, Stable Diffusion is open-source and offers a great deal of flexibility and offline functionality. Furthermore, while Stable Diffusion gives more control over technical elements like inpainting and outpainting, Midjourney is best at producing creative, stylized images with vivid details. Finally, while Midjourney requires a subscription, Stable Diffusion is free.
Q. Can I run Stable Diffusion without a graphics card?
Yes, you can use cloud-based programs like Google Colab or CPU-only derivatives like OpenVino to run Stable Diffusion without a graphics card. However, image production takes several minutes per pass in CPU-based configurations, which are far slower. Cloud systems offer faster performance without requiring local hardware.
Q. What is the principle of Stable Diffusion?
To produce coherent images, random noise is iteratively improved using the diffusion modeling approach, which is the basis for stable diffusion. This approach incorporates text conditioning through CLIP embeddings and lowers processing costs by using a latent space. The reverse diffusion method uses patterns discovered from large training datasets to recover high-quality images from noise.
Talk With Our Expert
Our Latest Insights




USA
Debut Infotech Global Services LLC
2102 Linden LN, Palatine, IL 60067
+1-703-537-5009
[email protected]
UK
Debut Infotech Pvt Ltd
7 Pound Close, Yarnton, Oxfordshire, OX51QG
+44-770-304-0079
[email protected]
Canada
Debut Infotech Pvt Ltd
326 Parkvale Drive, Kitchener, ON N2R1Y7
+1-703-537-5009
[email protected]
INDIA
Debut Infotech Pvt Ltd
C-204, Ground floor, Industrial Area Phase 8B, Mohali, PB 160055
9888402396
[email protected]
Copyright © 2025, Debut Infotech. All rights reserved. | Privacy Policy
Leave a Comment