Future of Text-to-Speech Models Explained for 2025
G
by
Gurpreet Singh
20 MIN TO READ
January 28, 2025
G
by
Gurpreet Singh
20 MIN TO READ
January 28, 2025
Table of Contents
What are Text-to-Speech Models?
Types of Text-to-Speech Models
Key Features of Text-to-Speech Models
Why Choose Open Source Text-to-Speech Models?
Applications of Text-to-Speech Models
Integration with Generative AI
Challenges in Text-to-Speech Implementation
Future of Text-to-Speech Models
Conclusion
Frequently Asked Questions
With the use of text-to-speech models, computers can now translate written text into speech that sounds very natural, which is completely changing the way we engage with technology. Virtual assistants, accessibility tools, content production, and customer support are just a few of the many uses for this cutting-edge technology that is driven by AI developments. Being a leader in Generative AI Integration Services, Debut Infotech is aware of the increasing relevance of Text-to-Speech Models and their transforming power in many different sectors.
We will talk about the basics of Text-to-Speech Models, and the technologies that make them work. Additionally, we will explore the advantages of open-source solutions such as open-source text-to-speech systems in this piece. We will also go over general trends in generative AI models, how businesses may efficiently combine them, and the part generative AI development companies play in determining the direction of human-computer interaction.
Explore Our Text-to-Speech Development Services
Leverage our comprehensive AI integration and development expertise to build customized, high-quality Text-to-Speech Models tailored to your needs. Discover how we can help!
TTS models are frameworks driven by artificial intelligence that can transform written text into spoken words. These systems synthesize speech that quite closely resembles human voices using generative AI frameworks and sophisticated neural networks. Modern TTS systems use generative adversarial networks (GANs) to increase accuracy, tone, and adaptability as well as text-to-speech open source AI.
The two main steps in the technology underpinning TTS are text preprocessing and speech synthesis. Text preprocessing entails analyzing and formatting the incoming text, while speech synthesis converts it into audio signals. Open-source solutions such as open TTS and open-source voice synthesizer frameworks have democratized access to this innovative technology, therefore allowing companies and developers to produce personalized and effective TTS solutions.
Types of Text-to-Speech Models
Many changes have been made to Text-to-Speech Models (TTS models), resulting in the development of different types to meet different needs. The main several forms of Text to speech models are shown below:
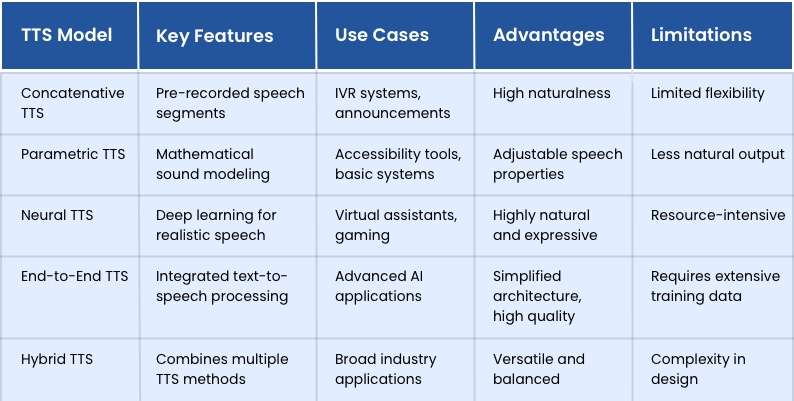
Concatenative TTS Models These classic models create speech by combining pre-recorded bits of human voice. Although they generate excellent, natural-sounding output, their versatility is restricted as they depend on a fixed collection of recordings.
Parametric TTS Models To mimic human speech, parametric models use mathematical parameters to simulate different voice intonation patterns. Though less realistic than concatenative models, they provide more freedom in changing speech qualities including tone, speed, and pitch.
Neural TTS Models Deep learning allows neural TTS models such as Tacotron, WaveNet, and FastSpeech to produce quite natural and expressive speech. In terms of quality, these models are the most advanced because they analyze and create speech patterns by copying human intonations and pronunciations.
End-to-End TTS Models These state-of-the-art models make speech synthesis easier by using a single neural network for text processing, linguistic feature extraction, and waveform production. FastSpeech 2 and Tacotron 2 are two examples of end-to-end systems that provide lightning-fast and high-quality results.
Hybrid TTS Models Combining elements of several TTS types, hybrid systems balance speed, quality, and resource economy. As an example, to make things more flexible, they might combine concatenative methods with neural networks.
Comparison of TTS Models
These diverse Text-to-Speech Models allow businesses to select solutions tailored to their specific requirements, ensuring optimal outcomes across industries and applications.
Key Features of Text-to-Speech Models
A wide range of sectors can benefit from text-to-speech models since they use cutting-edge AI approaches to generate realistic voices. The key features that make Text-to-Speech models essential in contemporary applications are listed below:
1. Natural Language Processing (NLP) Integration Text-to-Speech models are notable for their connection to advanced Natural Language Processing (NLP) systems. Beyond simple word conversion, NLP helps these models to grasp and comprehend text contextually. As a result, the speech that is generated has the right amount of pauses, emphasis, and emotional tone, making the exchange feel more natural. Thanks to NLP’s contextual comprehension, for instance, words like “I’m excited!” and “I’m nervous…” are represented differently in speech.
2. Scalability and Customization A key feature of open source TTS models is their flexibility to grow and change as needed. These models are great for call centers, e-learning platforms, and media creation because they can handle large-scale speech synthesis tasks quickly and easily. Additionally, customization options let businesses make voice tones that are unique to their brand, giving their products and services a unique look. Scalability and personalization guarantee uniform user experiences regardless of the virtual assistant’s personality or the tone of the voicemail.
3. Compatibility with Generative AI Trends These days, TTS systems are very similar to creative AI trends, which makes it easy to combine them with other AI-based technologies. Generative AI models can improve TTS systems, for example, to offer dynamic interactions in gaming settings, personalized speech patterns, or real-time translations. From producing convincing voices in virtual reality experiences to running conversational AI in customer service, these features increase the applications of TTS. TTS’s ability to adapt to changing AI trends guarantees its continuous significance in many different sectors.
4. Multilingual and Multimodal Capabilities Designed for a worldwide audience, advanced text-to-speech models sometimes accommodate several languages and dialects. Combining voice synthesis with visual components, like subtitles or sign language avatars, further enhances their usability and ensures inclusivity through multimodal capabilities. Because of these qualities, TTS is very useful in fields such as accessible technology, entertainment, and education.
5. Cost-Efficiency with Open Source TTS Solutions When you use open source text-to-speech AI options, you can cut down on development costs without affecting performance. Self-hosted text-to-speech is a system that allows companies to keep control of their data and save recurring license costs. This low-cost method makes it possible for even new businesses to use cutting-edge TTS technology.
With its combination of efficiency, versatility, and user-centric design, these fundamental aspects show why Text-to-Speech Models are essential in the modern digital world. TTS models keep stretching the bounds of creativity whether they are used to improve consumer interactions, run generative AI frameworks, or design novel user experiences.
Why Choose Open Source Text-to-Speech Models?
Cost-Effectiveness
The development of in-house TTS systems can be quite expensive. Open-source solutions like open TTS and TTS AI open source minimize license expenses, making them a budget-friendly option for startups and organizations.
Customization
Open source TTS models provide unmatched flexibility, in contrast to pre-packaged alternatives. Businesses can fine-tune voice tones, dialects, and speech tempo to match their unique requirements.
Community Support and Collaboration
Developers and academics from all around the world work together to power the ecosystem. Constant upgrades help solutions like open source text-to-speech AI to maintain their state-of-the-art status.
Transparency
Businesses can assess and enhance their voice synthesis open source systems with access to the underlying code, therefore guaranteeing security and best performance.
Applications of Text-to-Speech Models
The ability of text-to-speech models to improve user experiences and eliminate communication barriers has caused a revolution in several sectors. Because of their adaptability, they are crucial in many fields; they boost engagement, accessibility, and operational efficiency. These models have several notable uses listed below:
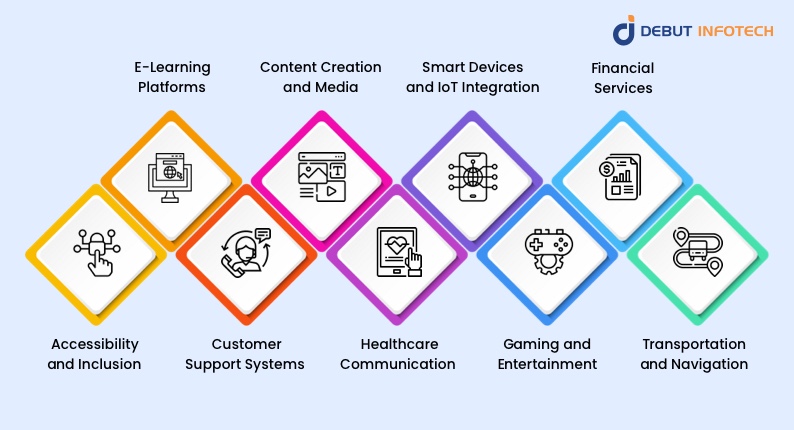
1. Accessibility and Inclusion For those with disabilities like visual problems or reading challenges, text-to-speech models are quite important in stimulating accessibility. These methods guarantee that digital materials become inclusive to everyone, independent of physical or cognitive constraints by translating text into spoken speech. For educational and governmental sectors, self-hosted text-to-speech technologies offer not only inclusive experiences but also data security benefits.
2. E-Learning Platforms To put it simply, TTS has been innovative in the field of distance learning. To make textbooks, assignments, or lectures audio-only, platforms can employ open-source text-to-voice technology. Students with visual impairments or those who learn best through auditory means will find this method particularly useful because of its adaptability, interactivity, and accessibility. TTS models’ multilingual capabilities improve worldwide e-learning opportunities by crossing language barriers among many student communities.
3. Customer Support Systems Open source text-to-speech technologies are commonly used by customer support systems to generate automatic responses that sound human. By guaranteeing clear, natural, and contextually relevant communication, these models improve user experience whether via IVR systems, chatbots, or virtual assistants. Using AI-driven TTS systems helps companies to effectively manage large client inquiries while lowering running expenses.
4. Content Creation and Media Text-to-audio models are becoming more and more important for content creators, bloggers, and media outlets turning written material into interesting auditory forms. Among the outputs made available with TTS technology are podcasts, audiobooks, and explanatory films. Cost-effective options for translating vast amounts of material are offered by open source text-to-speech AI, allowing artists to reach audiences who would rather listen than read.
5. Healthcare Communication There are uses for TTS devices in healthcare, where they help with communication and taking care of patients. TTS guarantees accurate and easily available delivery of important information from automated reminders for prescribed medications to voice-guided directions for medical equipment. Telemedicine also is quite important since it gives patients a more engaged experience.
6. Smart Devices and IoT Integration Text-to-speech models are being used a lot more now that smart home gadgets and IoT systems are becoming more popular. TTS allows smart appliances and virtual assistants (Alexa, Google Assistant) to connect with consumers. Driven by open-source TTS models, these uses leverage the natural-sounding voice synthesis capabilities of contemporary TTS technology to improve user experience.
7. Gaming and Entertainment Speech synthesis open source tools are applied in the gaming and entertainment sectors to produce dynamic dialogues and immersive worlds. From in-game character voices to narration in interactive storytelling, TTS models help creators increase player involvement while lowering the production costs related to voiceover recording.
8. Financial Services Automated alerts, fraud notifications, and balance updates are just a few of the services that financial institutions use TTS for. These companies guarantee safe, scalable, real-time communication with their customers by using text-to-voice open source solutions.
9. Transportation and Navigation Commuters rely on TTS for real-time updates, which is why it is crucial in transportation systems. Among the uses are in-flight instructions, GPS-guided navigation systems, and announcements at rail stops. While producing exact, context-aware audio outputs, open source voice synthesizers assist in lowering expenses.
Integration with Generative AI
Text-to-speech models and generative AI frameworks merging have opened a fresh world of opportunities. These models are being used by generative artificial intelligence development companies more and more to produce immersive user experiences.
Real-Time Language Translation
Combining TTS with generative adversarial networks will enable companies to provide real-time language translating services, removing communication restrictions.
Personalized Interactions
By changing speech outputs based on what users want. Generative AI trends allow companies to make interactions that are very specific to each person.
Advanced Simulations
Generative AI models improve TTS capacity in sectors including virtual reality and gaming to produce realistic in-game dialogues and settings.
Challenges in Text-to-Speech Implementation
Technical Complexity Developing and implementing Text-to-speech models calls on a thorough grasp of artificial intelligence, deep learning methods, and natural language processing (NLP). Expertise in machine learning methods like transformers or recurrent neural networks (RNNs) is typically necessary to run these models, which can be resource-intensive and complicated. Usually working with generative AI consultants who contribute knowledge in these cutting-edge domains will help companies develop such systems efficiently. Moreover, adjusting a TTS model to suit certain language requirements or accents could complicate the learning process even more. This usually makes the creation process take longer and cost more.
Data Privacy Concerns While open source voice synthesis tools offer transparency and the ability to customize, Businesses must handle the inherent data privacy risks with open source voice synthesis systems, notwithstanding the transparency and customization options. These tools handle personal information depending on the use case and translate delicate textual data into speech. Dealing with text-to-speech technology presents a great difficulty in ensuring compliance with worldwide data privacy legislation such as GDPR, HIPAA, or CCPA. By keeping data processing within the infrastructure of the company and lowering the danger of data leakage, self-hosted text-to-speech solutions also help to address this compliance problem. Still, companies have to create strong security systems to protect user information all through the deployment and running phases.
Voice Quality and Realism A major obstacle in the use of TTS is achieving human-like speech quality. The challenge of accurately simulating human speech remains, despite the substantial advancements in open source TTS models and speech synthesis open source solutions. Lack of training data for less prevalent languages, dialects, or specialized sectors could lead to robotic-sounding voices or incorrect pronunciation. Many companies use TTS leaderboard rankings to assess the success of the current models, therefore making sure they get the most cutting-edge solutions for their particular requirements. But speech quality and computational efficiency always have trade-offs, hence companies must find the ideal balance for best results.
Future of Text-to-Speech Models
Experts predict that text-to-speech models will improve in accuracy, flexibility, and usability as AI technology develops further. Important developments include:
Improved Multilingual Support: The next generation of text-to-speech systems will be able to effortlessly support a much larger variety of languages and dialects.
Integration with Generative AI Trends: Virtual influencers and AI-driven storytelling are two developing areas where TTS solutions will be absolutely important.
Advancements in Self-Hosted Solutions: As companies place a premium on data protection and personalization, self-hosted speech-to-text systems will become more popular.
Ready to Elevate Your Business with Cutting-Edge Text-to-Speech Solutions?
Contact us today to discuss how our expertise in Text-to-Speech Models and AI-driven solutions can transform your operations. Let’s bring your ideas to life!
With the help of text-to-speech models, computers will soon be able to converse with humans in a way that feels natural and effortless. These technologies provide boundless potential for creativity, ranging from open-source TTS models to state-of-the-art generative AI frameworks.
At Debut Infotech, we are dedicated to enabling companies to fully use Text-to-speech models. Our knowledge and experience will guarantee a smooth integration and great results whether you are investigating open-source ai text to speech or want to hire generative AI developers. Get in touch now to learn how we may realize your vision.
Frequently Asked Questions
Q. What are Text-to-Speech Models?
Text-to-speech (TTS) Models are computer programs that use artificial intelligence to transform written text into audible speech. They create human-like audio using sophisticated technology including speech synthesis and natural language processing (NLP). Applications ranging from smart gadgets to customer service systems to accessibility tools make extensive use of these concepts.
Q. How do Text-to-Speech Models work?
TTS models comprehend the context, tone, and pronunciation by processing incoming text via NLP. Then a speech synthesis engine turns the processed text into audio. Modern open source text-to-speech AI systems also create more natural-sounding speech employing deep learning.
2. Parametric TTS: Generates speech using algorithms and parameters like pitch and tone.
3. Neural TTS: Utilizes deep learning to produce high-quality, natural-sounding voices.
Q. How is TTS used in accessibility?
TTS is crucial for accessibility, helping individuals with visual impairments or reading challenges access digital content. For instance, self-hosted text-to-speech solutions allow organizations to convert text into speech securely, ensuring inclusivity while maintaining data privacy.
Q. What is the difference between open source TTS and commercial TTS solutions?
Open source TTS solutions, like those using open source voice synthesis, are customizable, cost-effective, and allow developers to modify the code for specific needs. Commercial solutions, on the other hand, are pre-packaged, often easier to use, and come with technical support but may have licensing fees.
Q. What are some key features of modern TTS models?
Modern TTS models include:
1. Natural language processing for context-aware speech.
2. High scalability for large-scale applications.
3. Compatibility with generative AI frameworks for advanced applications like real-time translations.
4. Customizable voices for brand-specific tones.
Q. Why are TTS models important for businesses?
TTS models enhance user experience by providing auditory interfaces, improving accessibility, and automating communication processes. Businesses can integrate TTS into applications like e-learning, customer support, and content creation to increase engagement while reducing operational costs. Solutions like open source text-to-voice platforms are particularly valuable for their flexibility and affordability.






Leave a Comment