Table of Contents
Our Global Presence :
Home / Blog / AI/ML
Understanding the Role of Embedding in Models Like Chat-GPT
by
March 15, 2024

by
March 15, 2024
There are still some users who doubt the validity of the models that form the core of ChatGPT, thus its popularity in business use is still growing. The training of machine learning models still remains the key for successful AI application development, e.g., ChatGPT. Nevertheless, some of natural language processing use cases depend on a concept called vector embeddings for greater model accuracy and efficiency.
In short, an embedding in the natural language processor refers to the probability/weight of a particular word being next in the sentence or phrase. Thus, the task of writing becomes more bearable as natural language processors are able to generate or understand language that is more human-like in the end. This is done by the system weighing the importance of the various words which are available in the large quantity of the text data online.
This article explores the workings of ChatGPT integration. It also discusses how advanced ChatGPT-like models use embeddings and build an app with ChatGPT.
What Are Embeddings?
An embedding approach employs a set of numbers to express complex data, e.g., text or pictures. It provides the opportunity for putting in motion big inputs by encoding high-dimensional vectors into a lower-dimensional space. To move the comparison and processing of the data forward, the method captures the meaning of the inputs semantically and brings together similar inputs in the embedding space.
The use of embeddings enables the leveraging and reusing across models, which is one of the main benefits of this method. This means ontology can be applied to a wide range of tasks, including sentiment analysis, image recognition, and text categorization once it is built. Let’s take an example sentence: “The main benefit of voting is: that the answer can easily be translated into a vector in any arbitrary space.” You can compare the numbers of the sentence with other sentences and determine the meaning of this sentence. We can compute the degree of similarity in the meanings of two given sentences by measuring the distance between their embeddings.
Text embeds are not the only kind of embeds. Furthermore, they can present images as a group of figures that correspond to the images’ features. The numbers can then be fed to text embeddings to see if a given sentence really contains enough information about the picture.
In machine learning, embeddings represent a widespread core method that is applied mostly with collaborative filtering to design recommendation systems. They can improve the model’s performance, shorten the training and prediction procedures, and are helpful for applications involving item similarity. Embeddings are widely used in recommender systems, image recognition, and natural language processing as they encode complicated data structures in a compact way. Without any doubt, they are foundational for learning algorithms of modern machines.
Embeddings: How Are They Stored And Accessed?
Embeddings here talk about the data, but where and how are they stored and retrieved? This is the place where the idea of a vector store comes under use. Embeddings can be stored and retrieved efficiently via a type of data structure called vector store. Most machine learning objectives require vector operations that can be applied to vector-based embeddings, such as vector addition and cosine similarity. In any case, vector stores act as word embeddings and can perform tasks like analogies and semantic similarities of natural language processing.
To understand vector storage, first look into how embeddings are formed.
For instance, you are required to take text into smaller units, e.g., words or sentences, that eventually form embeddings. Word clusters which are built from a neural network approach like Word2Vec, GloVe, or FastText using massive text corpora for mapping words to high-dimensional vectors based on their co-occurrence, can be employed in this process. These embeddings are beneficial to tasks like named entity recognition and sentiment analysis since they represent each unit syntactically and semantically. The models’ accuracy is increased by getting more detailed info using chunked text processing.
A database called the “vector store” holds embeddings as high-dimensional vectors, each associated with a distinct word. It can be used for tasks like constructing sentence representations or locating similar terms. Key-value lookups are performed using vector storage, in which a word is utilized as the key, and the matching embedding vector is retrieved as the value. It allows for quick and effective vector operations, like adding and subtracting vectors or calculating the cosine similarity between two embeddings. Machine-learning tasks such as sentiment analysis, text classification, and language translation can benefit from these procedures.
Importance Of Embedding
Machine learning models called transformers are critical to ChatGPT and similar services. These models have special features such as reversible soft weights, akin to a dynamically typed programming language’s read-eval-print loop (REPL). Transform models with embedded layers add a new layer of reduced dimensionality, enabling more sophisticated data analysis and better classification and interpretation of human language. A model’s capacity to understand complicated data is improved by embeddings, which produce a low-dimensional space to represent high-dimensional vectors.
Dimensionality is the shape of the data. Embeddings are essential for enhancing performance since they are a potent strategy for machine learning applications such as natural language processing. Embeddings are significant for the following reasons:
- Semantic representation: Embeddings simplify comparing and analyzing input data by capturing semantic meaning. Many natural language processing activities can perform better, including text categorization and sentiment analysis.
- Lower dimensionality: Many machine learning methods become less computationally complex and operate more efficiently with big inputs because embeddings produce a lower-dimensional space representing high-dimensional vectors.
- Reusability: An embedding is a potent and practical data analysis approach since it may be applied to various models and applications once produced.
- Robustness: Embeddings are robust and useful for many industry applications because they can be trained on big datasets and capture the underlying patterns and relationships in the data.
Types Of Embedding
Numerous approaches are available for creating embeddings in a deep neural network, each with advantages and disadvantages. The goal of the embeddings and the data type used are the only factors influencing the chosen approach. Whether using convolutional neural networks, recurrent neural networks, or another technique, having the appropriate approach can significantly improve the quality of the embeddings produced, accurately capturing the data’s underlying semantic meaning.
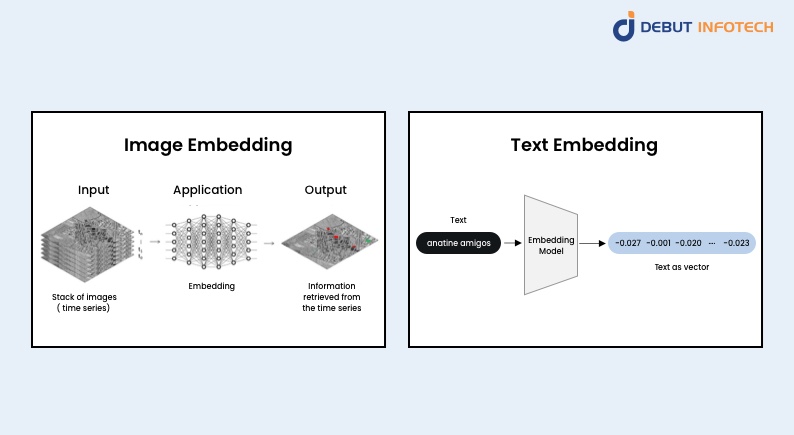
Image Embedding
The process of image embedding is examining images and producing numerical vectors that represent the attributes and properties of the image. Deep learning techniques are usually used, as they can extract features from an image and translate them into a vector representation. Numerous tasks, including object detection, image categorization, and image search, can be carried out with this vector representation.
Numerous picture embedding methods are available, each tailored to a particular purpose. While some embedding methods can be processed locally on the user’s PC, others need the photos uploaded to a distant server. One method that may be used locally and is especially helpful for fast image inspections without an online connection is the SqueezeNet embedder.
Text Embedding
Text embedding is a method that turns a character string into a vector of real numbers. This procedure makes what is known as an “embedding”—a space where the text can be embedded. Text encoding turns plain text into tokens and text embedding closely related concepts. The text embedding block in sentiment analysis is connected with the text encoding of the dataset view. It is crucial to remember that the text embedding block can only be utilized after an input block in which choosing a text-encoded feature is necessary.
Furthermore, it is imperative to guarantee that the language model adopted corresponds with the language model used for text encoding. Word embeddings are featured vectors for every real-valued word. NNLM, GloVe, ELMo, and Word2vec are some of the models that are made to train word embeddings.
How Can Embeddings Be Used
In real-world machine-learning applications, embedded systems are critical in boosting search engines, voice assistants, image recognition systems, and natural language processing, among other domains, by optimizing data representation and performance.
- Computer Vision
ChatGPT embeddings are used in computer vision to bridge contexts and facilitate transfer learning for applications such as AI Art Machines and self-driving cars. Models can be trained with visuals created from video games instead of real-world images by converting them into embeddings. Multiple transformations, from text to image and vice versa, are possible with this method.
- Semantic Search
By considering word context and meaning, BERT-based embeddings improve search results and help search engines understand subtle linguistic differences. To improve the relevance and accuracy of search results and user experience, a semantic search engine that uses BERT would be able to comprehend, for example, that a user was looking for directions on making pizza.
- Recommender System
A recommender system uses content-based and collaborative filtering to anticipate user preferences and ratings for entities or items. While content-based filtering employs embeddings to create associations between people and items, collaborative filtering leverages user activities to teach suggestions. Comparable items can be recommended to similar consumers by multiplying user embeddings by item embeddings, which generates rating predictions.
How Do Embeddings Work In A ChatGPT-Like Model?
Like other language models, ChatGPT generates text by combining machine learning and natural language processing methods. The text is initially tokenized into discrete units when you give ChatGPT a command like “Write me a poem about cats.” In this example, the tokenized text might include “Write,” “me,” “a,” “poem,” “about,” and “cats.”
A neural network is trained to anticipate a word or phrase’s context to create embeddings from the tokenized text. This facilitates the linking and comparing of various words or sentences. ChatGPT is a causal language model that uses a transformer architecture to anticipate the token that will come next in a sequence. Transformers leverage their ability to interpret data sequences, such as text, to identify words and produce replies. Transformer layers must be trained over several months using hundreds of GPUs, ingesting gigabytes of text data to help them understand the proper relationships between tokens.
Transformers are a type of neural network architecture that ChatGPT, an OpenAI machine learning model, utilizes to create text embeddings from user input. These embeddings are text representations in numerical form, where similar numbers represent words with comparable semantic meanings. The model determines which words to focus on to produce a response using several transformer layers. Each layer creates a new set of embeddings fed into the layer afterward. The last layer outputs a stop token, indicating the answer is finished. Word by word, ChatGPT generates text by predicting one token at a time. ChatGPT uses an autoregressive technique to produce longer text segments.
To elaborate, text is represented as high-dimensional numerical vectors in ChatGPT embeddings. These embeddings—which capture the text’s semantic and syntactic meaning—are essential to train the neural network to produce coherent and contextually appropriate responses.
Storing And Retrieving Embeddings On LLMs

A data structure called the Llama index makes it possible to do nearest-neighbour searches in high-dimensional spaces quickly and effectively. It can soon get similar vectors based on similarity metrics like cosine similarity because it works with embeddings and other vectors. The Llama index can benefit search engines, recommendation engines, natural language processing, and text classification. It does this by breaking up the high-dimensional space into smaller cells, or buckets, with a subset of the vectors contained in each.
The Llama index splits the vector into several low-dimensional subvectors using product quantization. Large datasets and machine learning applications can benefit from its key advantages, which include scalability, memory footprint reduction, and rapid and accurate nearest-neighbor searches.
Conclusion
Embeddings are high-dimensional numerical representations of words that help models understand and evaluate language more easily by capturing the context and meaning of text. The ChatGPT model benefits significantly from OpenAI’s embedding implementation since it can comprehend the connections between words and categories, producing more logical and contextually appropriate answers. Machine learning models become more accurate and efficient with the addition of embeddings, making highly efficient algorithms and more precise predictions. ChatGPT embeddings will become crucial in creating new applications as machine learning progresses.
FAQs
Q.What does a Chat-GPT-like model’s embedding mean?
A. Representing words or tokens as numerical vectors in a high-dimensional space is embedded in a Chat-GPT-like model.
Q. In what ways does embedding improve these models’ performance?
A. By capturing the semantic linkages between words, embedding helps the model comprehend the context and produce more logical answers.
Q. Which methods are frequently applied to embedding in models that resemble Chat-GPT?
A. For embedding these models, methods like Word2Vec, GloVe, and contextual embedding techniques like BERT are frequently used.
Q. Is it possible to adjust or tailor embedding for a particular task?
A. Indeed, during model training, embedding may be adjusted to suit particular tasks, enhancing task performance like question answering and sentiment analysis.
Q. What role does embedding play in improving the efficiency of Chat-GPT like models?
A. By compressing input data into a more digestible format, embedding allows Chat-GPT-like models to infer more quickly and with less computing complexity.
Talk With Our Expert
Our Latest Insights




USA
Debut Infotech Global Services LLC
2102 Linden LN, Palatine, IL 60067
+1-703-537-5009
[email protected]
UK
Debut Infotech Pvt Ltd
7 Pound Close, Yarnton, Oxfordshire, OX51QG
+44-770-304-0079
[email protected]
Canada
Debut Infotech Pvt Ltd
326 Parkvale Drive, Kitchener, ON N2R1Y7
+1-703-537-5009
[email protected]
INDIA
Debut Infotech Pvt Ltd
C-204, Ground floor, Industrial Area Phase 8B, Mohali, PB 160055
9888402396
[email protected]
Copyright © 2025, Debut Infotech. All rights reserved. | Privacy Policy
Leave a Comment