Table of Contents
Our Global Presence :
Home / Blog / AI/ML
Building and Deploying Machine Learning Pipelines: A Comprehensive Tutorial
by
June 26, 2024

by
June 26, 2024
Often overlooked when developing a machine learning model is the infrastructure required for training and serving the model in a production setting. It might be difficult to handle all the application, platform, and resource requirements for end-to-end machine learning development services.
Machine learning applications are different from traditional web deployments in terms of their footprint. An inference phase, on the other hand, is quick and light, but a training phase requires a lot of resources. The tools and frameworks required to run all of these components will also be required. Kubeflow is a well-liked open-source framework that may be used to create a standard for delivering machine learning applications from start to finish.
What Is Kubeflow?
Kubeflow is an open-source project that includes a selection of frameworks and tools. Making the development, deployment, and management of portable, scalable machine learning workflows simple is the main objective of Kubeflow.
Kubernetes is an open-source framework for managing containers that is the foundation upon which Kubeflow was created. An essential component of Kubeflow’s functionality is that Kubernetes is designed to function reliably in a variety of situations. With Kubeflow, you can concentrate on creating and managing machine learning workflows, which include handling data, executing notebooks, building models, and delivering them. Kubeflow is designed to let Kubernetes do what it does best.
TensorFlow Extended, an internal Google project, was the precursor of Kubeflow. It started as just a simpler means of executing TensorFlow tasks on Kubernetes, but it has now grown into a multi-architecture, multi-cloud framework for managing end-to-end machine learning workflows.
Kubeflow and Machine Learning Workflows
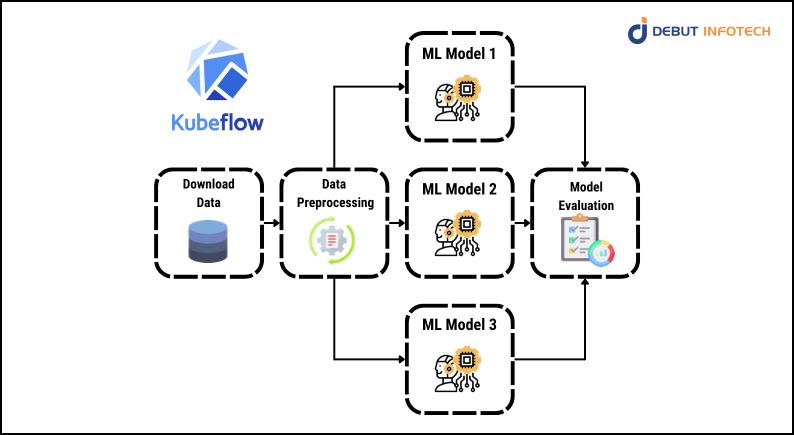
For data scientists and machine learning development companies, Kubeflow is a platform that combines the most useful features from both fields. Kubeflow allows data scientists to efficiently plan and coordinate their experiments on Kubernetes while experimenting with machine learning models.
Kubeflow is a tool that machine learning engineers can use to deploy machine learning systems to different environments for testing, development, and production.
Almost every step in the pipeline below is supported by a multitude of distinct components that make up Kubeflow. For instance, Kubeflow contains a component named “Katib” that is used to adjust the model’s hyperparameters. The main elements of Kubeflow will be covered later in this course.
How To Install Kubeflow
With Kubeflow, there are two methods to get started:
- Installing it using packaged distribution is easy and uncomplicated.
- Install it using the advanced manifests.
The maintainers of each packaged distribution develop and provide support for them. For instance, Microsoft maintains Kubeflow on Azure.
Principle Of Kubeflow
The capacity to compose
Composability is a principle of system design that addresses how components relate to one another. Because Kubeflow is very modular, you can quickly and simply employ different TensorFlow versions for different stages of your machine learning solutions development.
Mobility
Because of its portability, your machine learning project can operate in any location where Kubeflow is installed. It abstracts away all user issues and is platform agnostic. You only need to write your code once, and Kubeflow will take care of the abstraction, allowing you to run it on a cloud cluster or your laptop.
Scalability
Scalability is the ability of your project to release resources when not needed and to access more when needed. CPUs, GPUs, and TPUs are examples of computing resources that can vary depending on the environment.
Components of Kubeflow
Kubeflow components are logical blocks that together makeup Kubeflow. Generally, you will find yourself using one or more components in a machine learning solutions development.
Dashboard
Above all, the Central Dashboard provides quick access to other Kubeflow components. Some of the useful components are:
- Notebooks
An integrated Jupyter Notebook environment is included with Kubeflow. Writing machine learning applications, creating models, and conducting rapid tests may all be done in notebooks. Data scientists and ML engineers frequently run their notebooks locally and face resource limitations. Running operations where resources can be dynamically scaled is made easier by the presence of notebooks in the cluster.
- Pipelines
Building end-to-end portable and scalable machine learning pipelines based on Docker containers is made possible with the help of Kubeflow Pipelines, a potent Kubeflow component.
A series of steps called machine learning pipelines can handle any task, from gathering data to delivering machine learning models. Because each pipeline step is a Docker container, it is scalable and portable. You can reuse the pipeline’s parts since each step is autonomous.
- Experiments:
A Kubeflow component called Katib is made for large-scale, automated hyperparameter adjustment. Good model development heavily relies on hyperparameter tuning because it can be laborious to manually search a hyperparameter space.
With Katib, you may optimize the values of your hyperparameters around a specified metric (such as RMSE or AUC). It is a useful tool for determining and visualizing the best configuration to get your model ready for manufacturing.
Kubeflow Pipelines
There are numerous processes in a machine learning workflow, such as data preparation, model training, model evaluation, and more. Ad hoc tracking of these is challenging.
Another difficulty facing data scientists is monitoring model versions and recording experiments without the right tools. Data scientists can create machine learning processes using standards that are repeatable, shareable, and composable with Kubeflow Pipelines.
When creating machine learning code and deploying it to the cloud, data scientists may embrace a disciplined pipeline attitude with the aid of Kubeflow, a Kubernetes native solution. Kubeflow Pipelines’ ultimate objectives are to:
- Simplify Orchestration of Machine Learning Pipelines at scale
- Multi-tenancy enables quicker experimentation, reproducibility, and collaboration. Users can be added to groups with access control using the Kubeflow UI to create groups.
- Be reusable and provide uniformity for various machine learning components (pipeline phases).
Building blocks are not necessary for creating end-to-end machine learning solutions development with Kubeflow. In addition, Kubeflow facilitates a number of other features, including metadata logging, workflow scheduling, execution monitoring, and versioning.
Important Concepts in Kubeflow Pipeline
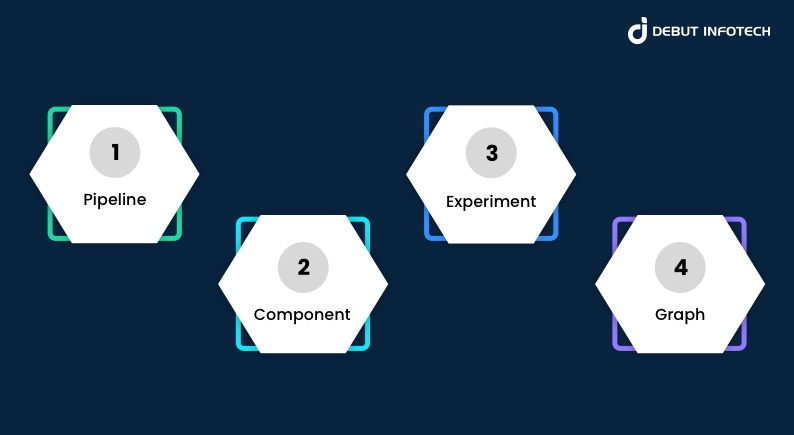
Some of the important concepts to note about Kubeflow Pipelines include:
Pipeline
A machine learning (ML) pipeline is a set of precisely specified phases in a workflow. The inputs (parameters) needed to execute the pipeline, as well as the inputs and outputs of each component, must be defined in the pipeline. Every element in a pipeline receives an input, processes it, and then sends the result to the element after it.
Understanding that every stage (or component) in a Kubeflow pipeline is a Docker container is crucial. When a pipeline is executed, Kubeflow launches one or more Kubernetes Pods that correspond to the pipeline’s parts. The code you wrote in the component is then executed by the Docker container, which is started by the pods.
Component
A pipeline component is a standalone piece of code that completes a specific task in the machine learning workflow, including training machine learning models, scaling data, or imputation of missing values.
A function and a component in a Kubeflow pipeline are comparable. As a result, every component has an output, an input, and a name.
To ensure that every stage of the pipeline is independent of the others and that you can combine and match different frameworks and tools in different sections of your machine learning workflows, every component in a pipeline needs to be packaged as a Docker image.
Experiment
You can run various pipeline setups in an experiment and compare and evaluate the outcomes. In machine learning, it’s typical to experiment with various parameters to determine which performs best. The goal of the Kubeflow Pipeline Experiment is to accomplish that
Graph
In the Kubeflow UI, a graph is a visual representation. With arrows denoting the parent/child relationships between the pipeline components represented by each step, it displays the steps that a pipeline run has completed or is currently completing.
Three ways to build pipelines in Kubeflow
Now that you know what Kubeflow pipelines are and why utilizing this framework to create and implement machine learning workflows in production has its advantages, maybe you can better understand them. Let’s quickly go over the three methods pipeline deployment and construction can be done using Kubeflow.
Interface for Users (UI)
Run pipelines, upload pipelines that someone has shared with you, see run output and artifacts, and plan automated runs are all possible with the Kubeflow UI.
Official Python SDK
ML pipelines can be developed and run programmatically using a collection of Python modules provided by Kubeflow. This is the most typical method that Kubeflow pipelines are used.
REST API
REST APIs are also offered by Kubeflow for systems that support continuous integration and deployment. Consider a scenario in which you would like to incorporate any of the Kubeflow Pipeline features into business procedures or systems that are downstream.
Kubeflow Pipeline Tutorial
Using a packaged distribution, which functions similarly to a cloud-based managed service, is the most straightforward approach to get started with Kubeflow. Here, the GCP Kubeflow service is being used. To discover how to deploy the service on GCP, follow this official guide.
You can use your GCP endpoint to access this dashboard after the deployment is successful.
Kubeflow Dashboard – Deployment on GCP
A few sample pipelines are included with Kubeflow pipelines. Let’s attempt a simple Python data preprocessing pipeline. Select the pipeline icon located in the toolbar on the left.
Kubeflow Pipelines – Deployment on GCP
Now, click on create experiment:
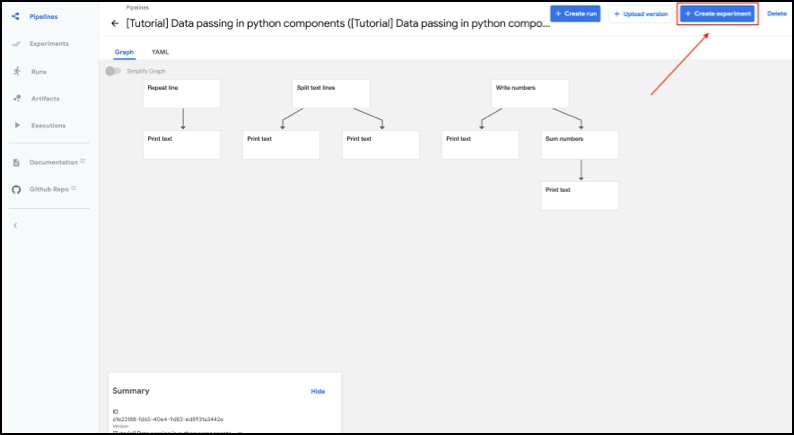
Kubeflow Pipelines – Deployment on GCP
To launch the pipeline, follow the instructions and then click the start button on the run screen.
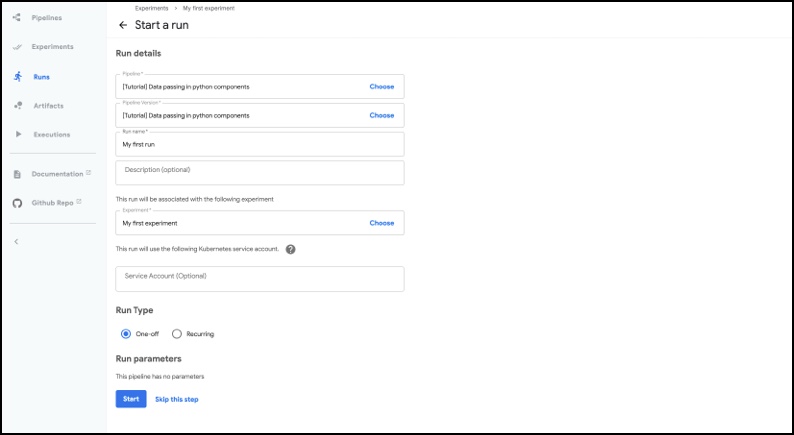
Kubeflow Pipelines – Deployment on GCP
The dashboard will display the experiment:
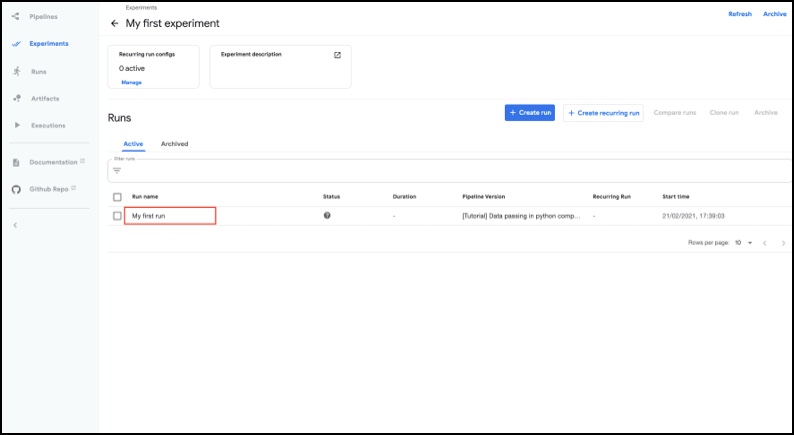
Kubeflow Pipelines – Deployment on GCP
To view the results after the run is complete, click on the experiment:
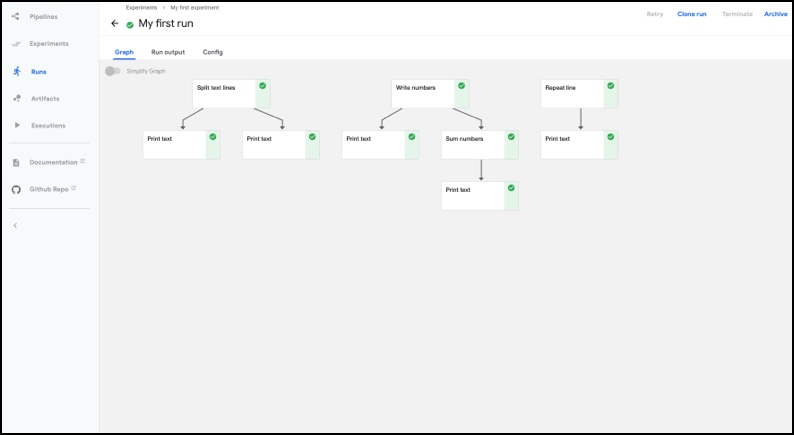
Kubeflow Pipelines – Deployment on GCP
You now understand how to use Kubeflow UI to execute pipelines. Every element in the pipeline depicted above is only a self-contained Python script. The steps in the following example are straightforward, such “Print Text” or “Sum Numbers.”
Let’s look at a more intricate example of how to use Python to code and compile these parts.
How To Build a Kubeflow Pipeline Using Python SDK
In this example, we will create a Kubeflow pipeline with two components:
- Download the zipped tar file based on the url passed as input,
- Extract all csv files and create a single pandas dataframe using the `pd.concat` function.
Theoretically, we could also write a single function that accepts the url, downloads the zipped file, and then combines all of the CSV files into a single file rather than splitting this process into two parts.
The advantage of doing things in two parts is that you may make a step for downloading the compressed file, which you can then utilize for subsequent tasks.
In Kubeflow, you can define the component as a yaml file and use the `kfp.components.load_component_from_url` function to load the component directly from the url.
First, let us load the component from this open-source URL.
“`
web_downloader_op = kfp.components.load_component_from_url(
‘https://raw.githubusercontent.com/kubeflow/pipelines/master/components/web/Download/component-sdk-v2.yaml’)
“`
For the second step, we will define a Python function:
“`
@component(
packages_to_install=[‘pandas==1.1.4’],
output_component_file=’component.yaml’
)
def merge_csv(tar_data: Input[Artifact], output_csv: Output[Dataset]):
import glob
import pandas as pd
import tarfile
tarfile.open(name=tar_data.path, mode=”r|gz”).extractall(‘data’)
df = pd.concat(
[pd.read_csv(csv_file, header=None)
for csv_file in glob.glob(‘data/*.csv’)])
df.to_csv(output_csv.path, index=False, header=False)
“`
As you can see, the `kfp.dsl.component} annotation has been added to the function. This annotation allows us to specify the place where the component definition (component.yaml) should be saved, the container image, and any package dependencies (in this case, pandas[1.1.4]).
Now, you can use the `pipeline} operator to connect these two parts in a pipeline.
Define a pipeline and use a component to generate a task:
@dsl.pipeline(
name=’my-pipeline’,
# You can optionally specify your own pipeline_root
# pipeline_root=’gs://my-pipeline-root/example-pipeline’,)
def my_pipeline(url: str):
web_downloader_task = web_downloader_op(url=url)
merge_csv_task = merge_csv(tar_data=web_downloader_task.outputs[‘data’])
# The outputs of the merge_csv_task can be referenced using the
# merge_csv_task.outputs dictionary: merge_csv_task.outputs[‘output_csv’]
“`
We can compile the pipeline after it has been defined. To assemble it, there are two methods. Using Kubeflow UI is the first method.
“`
kfp.compiler.Compiler(mode=kfp.dsl.PipelineExecutionMode.V2_COMPATIBLE).compile(
pipeline_func=my_pipeline,
package_path=’pipeline.yaml’)
“`
We can now upload and run this `pipeline.yaml` file using the Kubeflow Pipeline’s user interface. Alternatively, we can run the pipeline using the Kubeflow Pipeline’s SDK client.
“`
client = kfp.Client()
client.create_run_from_pipeline_func(
my_pipeline,
mode=kfp.dsl.PipelineExecutionMode.V2_COMPATIBLE,
# You can optionally override your pipeline_root when submitting the run too:
# pipeline_root=’gs://my-pipeline-root/example-pipeline’,
arguments={
‘url’: ‘https://storage.googleapis.com/ml-pipeline-playground/iris-csv-files.tar.gz’
})
“`
Tutorial Reproduced from Kubeflow Official.
In case this pipeline has to be expanded to incorporate a machine learning model, we will develop a Python function that accepts {Input[Dataset]} and fits the model with any preferred framework, such as PyTorch, Tensorflow, or sklearn.
After a function is generated, it must be edited to include the third task in the `my_pipeline` function. The pipeline must then be recompiled using either UI or `kfp.Client}.
Conclusion
Since machine learning is a complicated process, a distributed, scalable environment is needed. Although Kubernetes and Kubeflow are well-liked orchestration frameworks for machine learning tasks, Debut Infotech is a machine learning development company that can help you in developing and deploying Machine learning pipelines. Data scientists and developers can rapidly and easily construct and train models using Amazon Sagemaker, a fully managed machine learning development service, and then deploy those models directly into a hosted environment that is ready for production use. It offers an integrated platform for analysis and exploration using Jupyter Notebook.
You may use Azure’s capabilities to build, train, test, assess, and monitor machine learning models at scale. To guarantee scalability, stability, and ease of management, you can deploy your models using Kubernetes. These procedures are described in this article. Do you find the numerous, ever-evolving engineering principles overwhelming? Then contact Debut Infotech today and let the professional handle all the technicalities.
Frequently Asked Questions
Q. What is a machine learning pipeline?
A machine learning pipeline automates the entire process from data collection to model deployment, including preprocessing, feature engineering, training, and validation.
Q. What is the significance of machine learning pipelines?
Pipelines facilitate the management of complicated tasks and the replication of outcomes by ensuring consistency, minimizing errors, and expediting the process.
Q. What constitutes a machine learning pipeline’s principal parts?
Data gathering, preprocessing, feature engineering, model training, validation, deployment, and monitoring are important elements.
Q. How would you manage pipeline data preprocessing?
Preprocessing includes automatic data scaling, encoding categorical variables, addressing missing values, and dividing data into training and testing sets for consistency.
Q. Which tool is typically used to construct pipelines for machine learning?
Scikit-learn, TensorFlow, Keras, Apache Spark, Airflow, and Kubeflow are a few well-liked tools.
Q. How is a machine learning model deployed?
Models can be deployed via packaging, exposing via an API, and connecting with cloud services or containerization tools such as Docker and Kubernetes.
Talk With Our Expert
Our Latest Insights




USA
Debut Infotech Global Services LLC
2102 Linden LN, Palatine, IL 60067
+1-703-537-5009
[email protected]
UK
Debut Infotech Pvt Ltd
7 Pound Close, Yarnton, Oxfordshire, OX51QG
+44-770-304-0079
[email protected]
Canada
Debut Infotech Pvt Ltd
326 Parkvale Drive, Kitchener, ON N2R1Y7
+1-703-537-5009
[email protected]
INDIA
Debut Infotech Pvt Ltd
C-204, Ground floor, Industrial Area Phase 8B, Mohali, PB 160055
9888402396
[email protected]
Copyright © 2025, Debut Infotech. All rights reserved. | Privacy Policy
Leave a Comment