Table of Contents
Our Global Presence :
Home / Blog / AI/ML
A Comprehensive Review of Parameter-Efficient Fine-Tuning
by
March 12, 2024

by
March 12, 2024
With the growth of pre-trained language models especially the emergence of large language models (LLM) with large amounts of parameters in billions, there has been outstanding success in many natural language processing tasks. However, challenges are adapting large language models to precise downstream tasks because of their large size and comptational demands, especially if the environment has low computational resources.
Parameter efficient fine-tunning (PEFT) offers an effective solution by reducing the number of fine-tuning parameters and memory usage while achieving comparable performance to full fine-tuning. The demands for fine-tuning large language models have led to sporadic development of PEFT. The PEFT approach is one where there are limited computational resources or where memory constraint limits the deployment of large models.
With PEFT fine-tuning optimized by selectively updating only a subset of parameters, pre-trained models are streamlined for adaptation to specific tasks without compromising their effectiveness. This technique has enhanced advanced language processing capabilities and made them accessible to a wider range of applications and users.
What is Parameter-Efficient Fine-Tuning?
Parameter-efficient fine-tuning is a method used to fine-tune large pre-trained models using small subsets of parameters, It is a method in the field of natural language processing (NLP) different from the traditional fine-tuning method which adjusts the whole pre-trained model during fine-tuning. For the PEFT, it targets and fine-tunes only the model’s imperative parameters that are important to a task. Hence, it is a fast fine-tuning technique and also it reduces memory usage during the fine-tuning process.
Only a small number of model parameters are fined-tuned while the majority of the parameters in the pre-trained large language model are frozen out, this, therefore, overcomes the challenge of catastrophic forgetting, this is a downside behavior observed during the full fine-tuning of LLM. Pre-trained representation of huge language fashion is an enormous ability that PEFT relies on. However, it enables a challenge-unique personalization through parameters with no heavy weights. It is a copy of computer vision technology known as transfer learning.
As large language models grow, fine-tuning them on downstream natural language processing (NLP) tasks becomes difficult, where computation becomes expensive and memory-intensive. These challenges are solved using Parameter-efficient fine-tuning (PEFT) by selectively fine-tuning a small subset of additional parameters and then keeping the majority of the pre-trained model constant. This allows for fine-tuning with constrained computational resources and helps avoid significant loss of previously learned knowledge in large models.
The PEFT method has shown efficiency across various tasks such as image classification and text generation, it utilizes only a fraction of the total parameters. The adjusted weights from fine-tuning can seamlessly integrate with the initial pre-trained weights.
The Difference Between Fine-Tuning And PEFT?
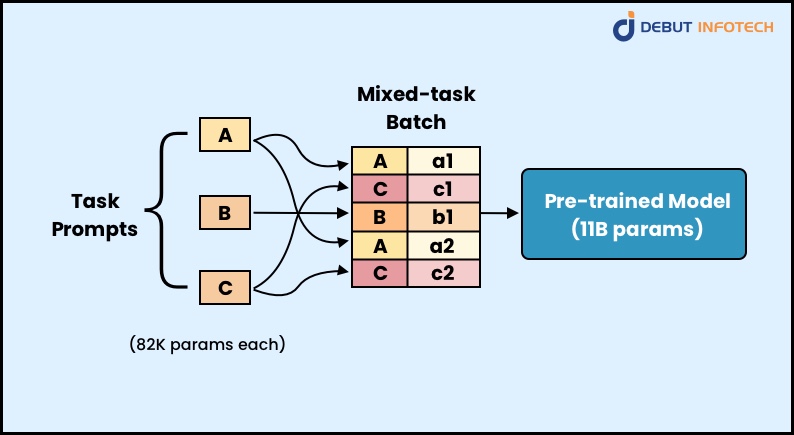
Fine-tuning and parameter-efficient fine-tuning are two methods used to improve the performance of pre-trained models in machine learning.
An aspect of deep learning is fine-tuning it constitutes a type of transfer learning. It involves the process of taking an already-existing model, which has been trained on a comprehensive dataset for an enormous task such as image recognition or natural language understanding, and making subtle corrections to its internal parameters. The purpose is to augment the model’s performance on a clean, correlated task without starting the training procedure all over.
In fine-tuning, a pre-trained model is trained further on new tasks using a new data set. Usually, the whole pre-trained model is trained in fine-tuning, including its layers and parameters. Hence for large models, the computational process is expensive and time-consuming and also makes use of large storage space. It involves making the model parameters to make it suitable for specific tasks after the model is pre-trained, it is then fine-tuned to perform certain tasks like text generation, etc.
In parameter-efficient fine-tuning, the focus is on training only a subset of the pre-trained model parameters. This method pinpoints the most important parameters for the new task and only updates those particular parameters during training. This enables peft to reduce the computation required for fine-tuning. The parameters of the pre-trained large language model are frozen, some new ones are added and these new parameters are fine-tuned on a new but small training data set so the new training data is specialized on the new task you fine-tune your LLM for.
PEFT: A Better Alternative To Standard Fine-Tuning
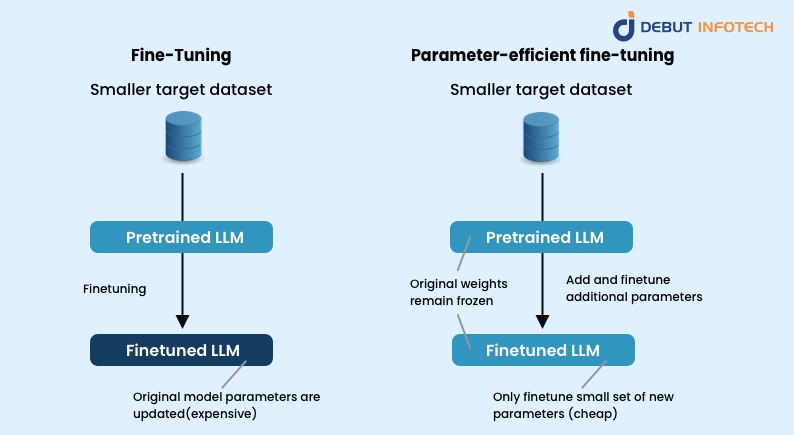
Parameter-efficient fine-tuning has been a better alternative for fine-tuning because fine-tuning the whole model is parameter inefficient as it always yields an entirely new model for each task. Hence, fine-tuning pre-trained models has been proven to be effective in a wide range of Natural language processing (NLP) tasks. Currently, many research works propose only to fine-tune a small portion of the parameters while keeping most of the parameters shared across different tasks. The PEFT model succeeds in achieving surprisingly good performance and is shown to be more stable than other corresponding fully fine-tuned counterparts, It has become one of the most promising techniques for NLP in recent years. It achieves state-of-the-art performance on most of the NLP tasks.
Apart from the efficiency of the parameter-efficient models, it has also been observed in many recent research works that the parameter-efficient methods achieve surprisingly good performance. These models are more stable and even achieve better overall scores than the fully fine-tuned models. Parameter-efficient fine-tuning (PEFT) techniques are a promising approach to efficiently specialize LLMs to task-specific data while maintaining reasonable resource consumption. PEFT can learn from two distinct datasets jointly without compromising performance.
Many view the PEFT method as the new pattern for using pre-trained language models (PLMs). Only a fraction amount of the parameters is tuned compared to full model finetuning, the PEFT methods claim to have achieved performance on par with or even better than fine-tuning.
Technique for PEFT
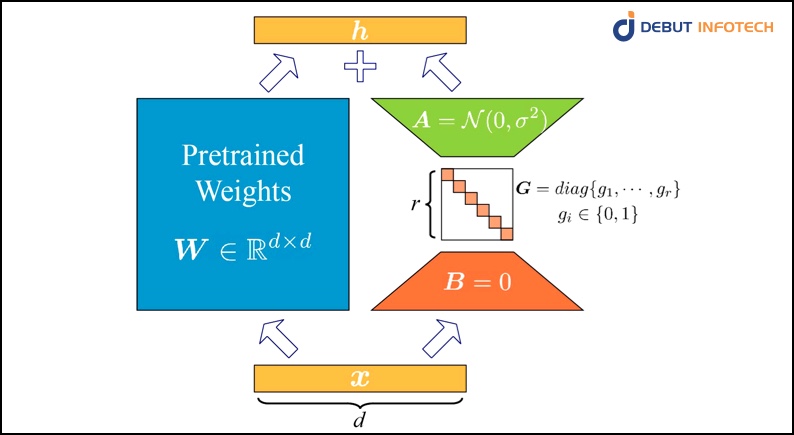
LoRA
LoRA is a technique in the PEFT method that relies upon the lower-ranking matrix for a fast and efficient training model. While traditional fine-tuning overhauls the entire model, LoRA on focuses refining only a smaller subset of parameters (Lower rank matrices). LoRA allows fast adaptation of models reducing computational burden. It requires smaller trainable parameters and it makes fine-tuning on enormous hardware possible. It maintains the original model quality and inference speed.
LoRA’s can curate leaner trainable parameters, which allows it to mitigate computational overhead synonymous with traditional fine-tuning methodologies. It carefully targets lower-rank matrices, Hence circumventing the need for exhaustive model reconfigurations, keeping the essence of the original architecture while enhancing adaptability.
LoRA possesses a very intuitive optimization strategy that boosts model quality and inference speed, maintaining a delicate balance between refinement and efficiency. In modern machine learning workflows, agility and performance are imperative. Hence, LoRA’s dynamism regarding parameter refinement and computational expediency makes it indispensable.
Prompt-Tuning
Prompt tuning is another PEFT technique for adapting pre-trained language models to specific downstream tasks. In prompt-tuning no training in the data set, you design and refine the input you give to a model to influence your result. prompt tuning involves learning soft prompts through backpropagation that can be fine-tuned for specific tasks by incorporating labeled examples.
At its core, prompt tuning shows the amazing synergy between unsupervised pre-training and supervised task adaptation, for optimal task performance, labeled examples are relied upon to calibrate soft prompts. prompt tuning comprises a symbiotic relationship between model versatility and task specificity, the dual capabilities of model pre-training and prompt customization are harnessed, and this results in enhanced efficacy across a spectrum of real-world applications.
Also, the iterative nature of prompt tuning encompasses a feedback loop wherein responses based on task-specific feedback models are refined iteratively, this caters to continual improvement and adaptability. Evolving task requirements are navigated seamlessly due to this iterative refinement process, thereby boosting model robustness. Prompt tuning is a paradigm shift in fine-tuning methodologies, whereby the emphasis shifts from data-intensive training regimes to the strategic manipulation of model inputs, ushering in a new era of efficiency and efficacy in natural language processing.
P-tuning
Pre-trained language models are improved for various tasks using P-tuning, a technique in the PEFT method. for instance, prediction of a country’s capital and sentence classification. The input embedding of the pre-trained language model is modified with differential output embedding generated using prompts. The continuous prompts can be optimized using a downstream loss function and a prompt encoder, which helps solve discreteness and association challenges.
The inherent challenges like discreteness and semantic association are catered for by this approach. A combination of loss functions and a dedicated prompt encoder are taken advantage of, and there is a seamless convergence between model inputs and desired task outcomes which P-tuning orchestrates. Thereby enhancing performance while preserving the integrity of the underlying model architecture.
Building pre-trained language models with the flexibility to navigate task nuances, P-tuning shows the powerful combination of efficiency and efficacy within contemporary natural language processing workflows.
Debut Infotech can leverage the power of neural networks to transform the provision of their services, Debut Infotech will employ the PEFT method in their services to seamlessly personalize solutions for their users, caring for the unique needs of each client while optimizing resources in their use of PEFT for LLM this will bring client satisfaction and product efficiency.
Conclusion
The PEFT method over the last few years has proven to be a good method in the natural language process field for fine-tuning in large language models. It has surpassed many of its contemporary methods due to its performance. while it ignores other parameters during the process of fine-tuning but focuses on the important parameters needed for the specific task. This has resulted in using less expensive computation resources and optimized memory usage.
FAQs
Q. What is parameter-efficient fine-tuning (PEFT) in the context of a large language model (LLM)?
A. It is a technique used to fine-tune pre-trained models using small sets of parameters. In this process, all other parameters in the model are frozen, and the focus is only on the parameter that is important to the specific task.
Q. What is fine-tuning?
A. In machine learning, fine-tuning is where a pre-trained model is trained further on new tasks using a new data set. The amount of fine-tuning can vary depending on the amount of available data and the similarity between the original and new tasks.
Q. What is prompt-tuning in parameter-efficient fine-tuning?
A. Prompt-tuning is a technique in the Peft method where you do not train data sets you design and refine input to suit your output.
Q. Why is PEFT a better alternative for fine-tuning?
A. Fine-tuning the whole model is parameter inefficient as it always yields an entirely new model for each task. Because of this parameter, efficient fine-tuning is a better alternative for fine-tuning.
Q. What distinguishes PEFT from traditional fine-tuning techniques?
A. PEFT employs a selective fine-tuning strategy, concentrating on the factors that have the greatest impact on the goal task. It does this by minimizing computational load utilizing methods including regularization, knowledge distillation, and parameter trimming.
Talk With Our Expert
Our Latest Insights




USA
Debut Infotech Global Services LLC
2102 Linden LN, Palatine, IL 60067
+1-703-537-5009
[email protected]
UK
Debut Infotech Pvt Ltd
7 Pound Close, Yarnton, Oxfordshire, OX51QG
+44-770-304-0079
[email protected]
Canada
Debut Infotech Pvt Ltd
326 Parkvale Drive, Kitchener, ON N2R1Y7
+1-703-537-5009
[email protected]
INDIA
Debut Infotech Pvt Ltd
C-204, Ground floor, Industrial Area Phase 8B, Mohali, PB 160055
9888402396
[email protected]
Copyright © 2025, Debut Infotech. All rights reserved. | Privacy Policy
Leave a Comment