ON THIS PAGE
Progress0%





Our Global Presence :

Deep learning is a form of intelligence that was created to imitate the neural networks and systems found in the human brain, which are crucial to cognitive function. Multimodal models uses Deep neural networks. The networks are made up of layers of artificial neurons that can analyze and process enormous amounts of data and learn and become better over time.
To understand their surroundings, humans use their five senses—sight, hearing, touch, taste, and smell. Multimodal learning is an AI field that combines information from diverse sources like text, image, audio, and video to gain a richer understanding, unlocking new insights and enabling diverse applications through techniques like fusion-based approaches. This article explores the foundations of multimodal learning, looking at several methods for merging data from different sources and how they are applied to autonomous cars and speech recognition.
A multimodal model is an artificial intelligence system that processes various types of sensory information at the same time, much like humans do. Unlike typical unimodal AI systems, which are trained to do a given task with a single sample of data, multimodal models are trained to integrate and evaluate data from multiple sources, such as text, images, audio, and video. This method includes the background and corroborating data necessary to make precise predictions, enabling a more thorough and detailed data comprehension.
Multimodal models yield more dynamic predictions than unimodal systems because they integrate disparate data from several sensors and inputs into a single model. They create high-level abstract representations from raw sensory data by utilizing deep learning techniques and sophisticated neural networks.
Raw sensory data is transformed into a comprehensive representation by the encoder layer, and data from several inputs is combined by the input/output mixer layer. Multimodal models provide a more sophisticated and perceptive approach to problem-solving and hold great promise for future development as they emulate the integration of numerous sensory inputs found in the human brain.
The development of artificial intelligence systems can be approached differently using the multimodal vs. unimodal paradigms. The multimodal model aims to integrate various data sources to assess a particular problem holistically. In contrast, the unimodal model concentrates on training systems to do a single task using a single data source. Below is a thorough analysis contrasting the two methods:
To answer the question, how do multimodal models work? Let’s consider the following.
Multimodal artificial intelligence integrates many data sources from distinct modalities, including text, pictures, audio, and video. Convolutional neural networks (CNN) are used for images, while recurrent neural networks are used for text. To begin the process, each unimodal neural network is trained on its unique input data. They consist of three primary parts, beginning with the unimodal encoders. The encoders are accountable for individually processing the input data from every modality. For example, a text encoder processes words, whereas an image encoder processes images.
The multimodal architecture consists of classifiers, fusion networks, and unimodal encoders. To achieve success, the fusion network integrates features from multiple modalities into a single representation. Methods such as cross-modal interactions, attention processes, and concatenation are proposed for this objective. After training on a particular task, the classifier guesses based on input or classes the fused representation into a particular output category.
This classifier makes the final judgment. Multimodal designs provide flexibility in merging various modalities and adjusting to novel inputs and tasks. Compared to unimodal AI systems, a multimodal model provides more dynamic predictions and improved performance by incorporating data from many senses.
Now let’s discuss how a multimodal AI model and architecture work for different types of inputs with real-life examples:
Powerful computer programs like CLIP, DALL-E, and GLIDE from OpenAI can create images from text and describe images. They resemble extremely clever robots that can interpret words and images and utilize that knowledge to produce new content.
CLIP is a multimodal model that predicts images linked to various descriptions using distinct image and text encoders. It has multimodal neurons that fire when exposed to text descriptions and visuals, indicating an integrated multimodal representation.
DALL-E is a 13 billion parameter variant of GPT-3 that pushes the boundaries of text-to-image generation by leveraging CLIP to produce precise and detailed images.
DALL-E’s replacement, GLIDE, creates more imaginative and lifelike pictures by using a diffusion model.
These models set a new benchmark for text-to-image and picture description creation, showcasing the multimodal model’s ability to produce coherent, high-quality descriptions and images from text.
Artificial intelligence (AI) systems have advanced significantly in multimodal activities related to video; Microsoft’s Project Florence-VL introduced ClipBERT in mid-2021. This innovation solves common video-language applications by combining CNN and transformer models.
ClipBERT evolutions, such as VIOLET and SwinBERT, use Masked Visual-token Modeling and Sparse Attention to achieve SotA in video question answering, retrieval, and captioning. All models use the same transformer-based architecture and parallel learning modules, in spite of their variations, to extract data from various modalities.
Web search benefits greatly from multimodal learning. A model’s job in this assignment is to find textual and image-based sources that can help with a query. For the majority of queries, however, more than one source is needed to determine the correct response. In order to generate a natural language response for the inquiry, the model must then reason using these inputs.
Multimodal search problems are addressed by Google’s A Large-scale ImaGe and Noisy-Text Embedding model (ALIGN). It trains visual and text encoders using noisy alt-text data from internet photos, fusing them using contrastive learning to create a model with multimodal representations that can do cross-modal searches without additional fine-tuning
When it comes to answering visual questions, it is difficult for a model to accurately respond to a question based on a picture. Microsoft Research has created some of the most effective methods for answering questions. METER, a comprehensive framework for training high-performing end-to-end vision-language transformers, is one such method. This framework employs multiple sub-architectures for the decoder, multimodal fusion, vision encoder, and text encoder modules.
The multimodal AI model known as the Unified Vision-Language Pretrained Model (VLMo) uses a modular transformer network to acquire dual and fusion encoders. It is composed of a shared self-attention layer and blocks containing modality-specific experts, providing flexibility for fine-tuning. These models have countless potential applications in providing complex answers with further investigation.
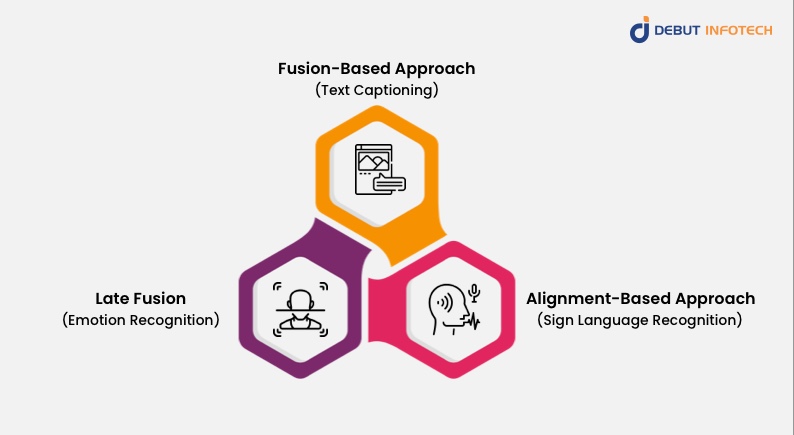
In the fusion-based method, the various modalities are encoded into a shared representation space. Then the representations are combined to construct a single modality-invariant representation that encompasses the semantic data from each modality.
Depending on when the fusion takes place, this strategy can be further broken down into early fusion and mid-fusion strategies.
An illustration of a fusion-based strategy is a caption that combines text and images. The method is called fusion-based because the semantic information from the text and the visual aspects of the image are encoded into a shared representation space, which is subsequently fused to create a single modality-invariant representation that combines the semantic information from both modalities.
In particular, a recurrent neural network (RNN) is used to extract the text’s semantic information, and a convolutional neural network (CNN) is used to extract the image’s visual features.
Next, a common representation space is created by encoding these two modalities. Concatenation or element-wise multiplication techniques are utilized to combine the visual and textual components into a single modality-invariant representation.
The caption for the picture can then be created using this final representation.
This method entails aligning the various modalities to enable direct comparison.
The objective is to develop modality-invariant representations that can be compared across modalities. This method works well in situations where there is a clear relationship between the modalities, such as audio-visual speech recognition.
This application calls for the model to align the temporal information of the auditory (waveform) and visual (video frames) modalities, which is why the alignment-based technique is involved.
The model’s job is to translate hand movements into text by recognizing them. A video camera records the gestures; in order to effectively interpret the gestures, the matching audio and the two modalities need to line up. To detect the movements and associated spoken phrases, this entails determining the temporal alignment between the video frames and the audio waveform.
The RWTH-PHOENIX-Weather 2014T dataset, which includes video recordings of German Sign Language (DGS) from multiple signers, is one open-source dataset for sign language recognition. The dataset can be used for multimodal learning challenges that call for alignment-based techniques because it contains both visual and auditory modalities.
This method combines the predictions from models that were trained independently on each modality. After that, a final prediction is produced by combining the individual guesses. This method works best when there is no direct relationship between the modalities or when the information provided by each modality is complementary.
Emotion recognition in music is a real-world illustration of late fusion. In this assignment, the model has to use both the auditory characteristics and the lyrics to identify the emotional content of a piece of music.
In this case, the late fusion strategy is used since it generates a final forecast by combining the predictions of models trained on different modalities (lyrics and auditory characteristics). Each modality is used to train the distinct models independently, and the predictions are then integrated subsequently. Consequently, late fusion.
The DEAM dataset contains audio characteristics and lyrics from over 2,000 songs and is intended for use in music emotion analysis and recognition. Word embeddings and bag-of-words are used to represent lyrics, whereas spectral contrast, rhythm characteristics, and MFCCs are used for audio features.
Late fusion can be used to merge the predictions of models that have been trained independently on each modality to provide a final forecast. The dataset can be subjected to the late fusion strategy by merging predictions from independent models trained on each modality.
Some of the real-life use cases of Multimodal models are listed below:
Multimodal models can be applied in the automotive industry. Multimodal learning improves robots’ skills by combining data from several sensors, including radar, lidar, and cameras. This improves the perception and response times of self-driving cars. A dataset from Google’s self-driving car division, Waymo Open Dataset, contains labels for bicycles, pedestrians, and cars, as well as high-resolution sensor data from Waymo’s vehicles. Tasks involving self-driving cars can use this dataset for object detection, tracking, and prediction.
Multimodal AI use cases also include speech recognition. Multimodal learning combines audio and visual input to improve speech recognition accuracy. Multimodal models reduce unpredictability and noise in speech signals by monitoring lip movements in addition to speech signals.
A multimodal dataset for voice recognition is the CMU-MOSEI dataset, which includes 23,500 sentences from 1,000 YouTube speakers. The accuracy of voice recognition and related tasks can be improved by using this dataset for speaker identification, sentiment analysis, and emotion recognition.
Using audio data and vocal characteristics, the Voice Recordings Analysis project is a multimodal learning application that seeks to determine an individual’s gender. The audio recordings of male and female English speakers used in this project include intricate details about each speaker’s vocal traits. This is one benefit of AI in media and entertainment.
Extracting parameters such as pitch, frequency, and spectral entropy can increase the prediction model’s accuracy and efficacy. These help the algorithm recognize patterns and trends regarding gender-specific voice characteristics.
Multimodal learning has developed into a powerful tool for combining many data sources to increase the accuracy of machine learning algorithms. Combining various data sources, such as text, audio, and visual data, can result in more reliable and accurate forecasts. This is especially true for the autonomous vehicle business, text and image fusion, and speech recognition.
However, multimodal learning presents several difficulties, including issues with co-learning, translation, alignment, fusion, and representation. These require considerable thought and focus.
Still, as machine learning methods and processing capacity advance, we should expect the introduction of even more sophisticated multimodal in the years to come.
Multimodal models are AI systems that integrate and process information from multiple types of data, such as text, images, and audio, to perform tasks more effectively.
Multimodal models work by combining different types of data inputs, like text and images, using advanced machine learning techniques to interpret and generate responses or actions based on the combined information.
Multimodal models are used in various applications, including virtual assistants, healthcare diagnostics, autonomous vehicles, and content creation, where understanding and generating information across different data types is crucial.
Multimodal models are important because they mimic how humans process information, leading to more accurate and context-aware AI systems that can handle complex tasks requiring multiple data types.
Challenges include integrating diverse data sources, managing the complexity of multimodal data, and ensuring the model can effectively learn and generalize from these different types of information.
Unlike traditional AI models that focus on a single data type (e.g., text or images), multimodal models can process and combine multiple data types simultaneously, resulting in more comprehensive and versatile outputs.
The future of multimodal models includes advancements in real-time applications, such as enhanced virtual assistants and more sophisticated AI-driven content generation, with improved accuracy and contextual understanding.
Our Latest Insights
USA
2501 Chatham, Rd Suite R Springfield, IL 62704
+1-708-515-4004
info@debutinfotech.com
UK
7 Pound Close, Yarnton, Oxfordshire, OX51QG
+44-770-304-0079
info@debutinfotech.com
Canada
326 Parkvale Drive, Kitchener, ON N2R1Y7
+1-708-515-4004
info@debutinfotech.com
INDIA
Sector 101-A, Plot No: I-42, IT City Rd, JLPL Industrial Area, Mohali, PB 140306
9888402396
info@debutinfotech.com


