Table of Contents
Our Global Presence :
Home / Blog / Tokenization
What is Data Tokenization and Why is it Important?
by
November 22, 2024

by
November 22, 2024
Did you know that 422.61 million data records were leaked in the third quarter of 2024 alone? Data breaches have been a concern since at least 2005 when many organizations and government entities switched from paper to digital records. Anytime confidential and sensitive information is leaked to malicious third parties, it has had a profound impact on individuals, government bodies, and various organizations. Different cybersecurity protection methods have been developed over the years to remedy this challenge, and data tokenization is one of the most prominent examples.
In this article, we’ll describe data tokenization, how it works, its benefits, and some common use cases across different industries.
Let’s get right to it
Overview of Data Tokenization
Data tokenization is a cybersecurity substitution technique for swapping sensitive data with a meaningless set of alphanumeric strings called tokens, thereby protecting the original data. In this technique, the tokens are created using a tokenization system’s algorithm and have no inherent meaning. Furthermore, they can’t be reverse-engineered to produce the original dataset, which is securely stored in a digital data vault. Instead, only the algorithm used to generate them randomly in the first place can be used to retrieve the original dataset.
This technique is similar to the process of replacing real money with chips at a casino. Instead of playing at the table with actual cash, players use casino chips, which have a specific monetary value. While you place bets with the casino chips, the casino securely keeps your money in a safe vault, and you can convert your chips back to money with the cashier at the end of your game. The casino chips, in this instance, are like the tokens in data tokenization, while the real money you swapped for them represents the original data that is converted to tokens by data tokenization systems.
Due to rising security concerns across digital systems, data tokenization is being increasingly used as a necessary security mechanism. It helps organizations keep their customers’ data safe even in the event of a system breach because the tokens are not useful to threat actors. It’s like trying to purchase something outside a casino with casino chips—the chips have no value unless they are converted to cash by the cashier.
Also Read What is Real Estate Tokenization
While this technique sounds pretty straightforward, some vital processes are involved in ensuring that really sensitive data are securely converted into tokens. Let’s explore this further in the next section.
How Data Tokenization Works: The Process of Converting Data into Tokens
The complex process of changing sensitive data such as a credit card number (PAN or Primary Account Number) and Personally Identifiable Information into tokens is done using a tokenization system in the following steps:
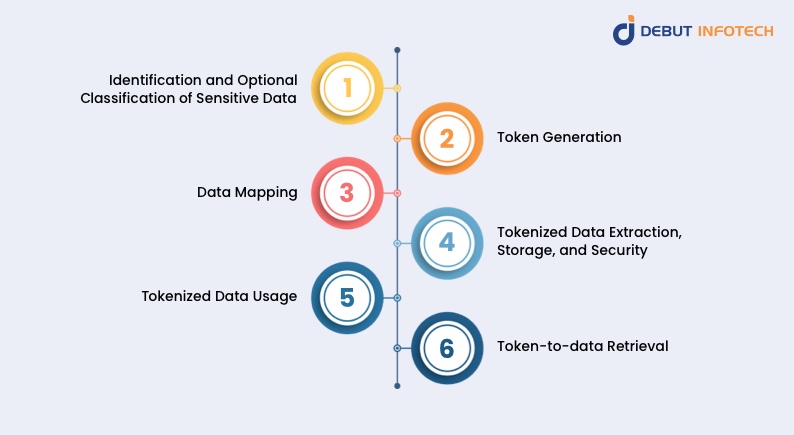
1. Identification and Optional Classification of Sensitive Data
Whether it’s a customer’s 16-digit primary account number (credit card number), social security number (SSN), PIN number, or any other example of sensitive data that requires protection in a customer data record, it has to be identified first. The organization or merchant processing this data piece has to single it out to the tokenization system explicitly. Furthermore, it must also state the exact data category it belongs. This is the first step in the data tokenization process.
2. Token Generation
A tokenization system takes over the remaining part of the process by handling the identified data directly. It transforms the data into unique, non-sensitive placeholders of alphanumeric strings called tokens, which are created at random. This system uses complex tokenization algorithms, secure databases, and encryption keys to manage the tokens.
3. Data Mapping
The tokenization system now establishes a clear relationship or link between the original sensitive data and the randomly generated tokens. This basically means explicitly identifying which token represents each data using a key-value map.
The system does this by constructing a mapping table or database for safe preservation. As a result, the tokenization system can recover the original data whenever necessary, such as during payment or customer verification.
4. Tokenized Data Extraction, Storage, and Security
Once the token map has been successfully established, the tokenization system moves the sensitive original data from the organization’s system to an isolated and segregated digital vault. This vault is usually an encrypted database entirely different from where the tokens are kept.
At the same time, the tokens are securely stored in a database together with any related metadata or background information. This way, the sensitive data remains inaccessible even in the event of a successful system breach because only the tokens can be accessed, and there’s no way to gain access or decipher the original data from the tokens.
5. Tokenized Data Usage
Whether the organization is processing payments or managing customer accounts, it can now continue its activities normally but using tokens instead of the original data. In the first place, the initial data is no longer on the internal system, so the tokens are used instead anytime the tokens are needed.
6. Token-to-data Retrieval
Anytime it is absolutely compulsory to use the original data, the tokenization engine retrieves it from the database using the mapping table as long as there is necessary authorization. A tokenization system must protect the entire infrastructure by implementing strong security measures.
This robust data security practice has relevant applications across various industries. In the following section, we will familiarize ourselves with some of the most common ones.
Create Smarter Tokenization Processes With AI
With the right AI tools, you can generate tokens that are near-impossible for hackers to reverse-engineer and take your data security to the next level.
Common Uses Cases of Data Tokenization
The following are its real-time applications and use cases:
1. Payment Processing
Data tokenization is increasingly being used to secure cardholder data in the payment industry. It replaces confidential payment data, such as credit card information, with tokens to make digital payment transactions more secure.
This application has become so widespread that payment tokenization has emerged as a subset of data tokenization. It helps to reduce the risks of data breaches and payment fraud.
2. Implementing the Principle of Least Privilege
The principle of least privilege is a fundamental cybersecurity concept that ensures users have the minimum level of data access required to perform their core functions. It means giving users only the littlest level of data access to do their jobs – no more, no less.
Tokenization already converts sensitive data to tokens and ensures that only authorized users can access the original sensitive data, making it a relevant technique for implementing this concept.
As such, it can be applied in the following scenarios:
- User Account Management: It helps to maintain the required level of access for different job roles.
For example, in the same organization, a receptionist may have access to common areas and basic systems but will be unable to access sensitive financial records. On the other hand, account managers will be able to view relevant client information but will be unable to access other clients’ data or administrative records.
- Software Development Environments: It restricts developer access depending on their job requirements in software development environments.
For instance, a developer working on a specific application might have permission to modify code and deploy updates but not to access production databases or sensitive configuration files. Furthermore, they can get temporary access to certain systems for maintenance tasks through just-in-time privilege escalations, which can be reverted after maintenance.
3. Third-party Data Sharing and Collaboration
With the help of data tokenization, an organization can still maintain data security and privacy even when sharing data with partners, vendors, or departments. Instead of sharing the exact data, the organization simply replaces them with tokens to avoid any risk or compliance requirements associated with letting a third party take control of that sensitive information.
4. Regulatory Compliance
Most organizations that collect customer data often have to adhere to strict compliance regulations like the General Data Protection Regulation (GDPR) and the Payment Card Industry Security Standard (PCI DSS). Data tokenization helps them to lower their compliance scope by reducing the amount of sensitive data stored within their systems. More so, tokens aren’t subjected to compliance requirements like the PCI DSS 3.2.1. Consequently, organizations get to save time and other resources required for maintaining compliance with these statutes.
5. Personally Identifiable Information (PII) Handling
Personally Identifiable Information includes individual information like emails, phone numbers, addresses, names, medical records, etc. Anytime these types of data go through data tokenization, they become de-identified. Therefore, it helps to maintain a significant level of privacy and even reduces the potential impact in the unlikeliest events of a breach or data theft.
Related Read – Protegrity Tokenization
There are many more potential applications and use cases of data tokenization across various industries. All of these enjoy the same fundamental advantage of securing sensitive data and reducing the surface area for data breaches and loss in the course of handling. Let’s take a look at the overall benefits of data tokenization below:
Advantages of Data Tokenization
Following are the benefits to organizations when it comes to handling sensitive data:
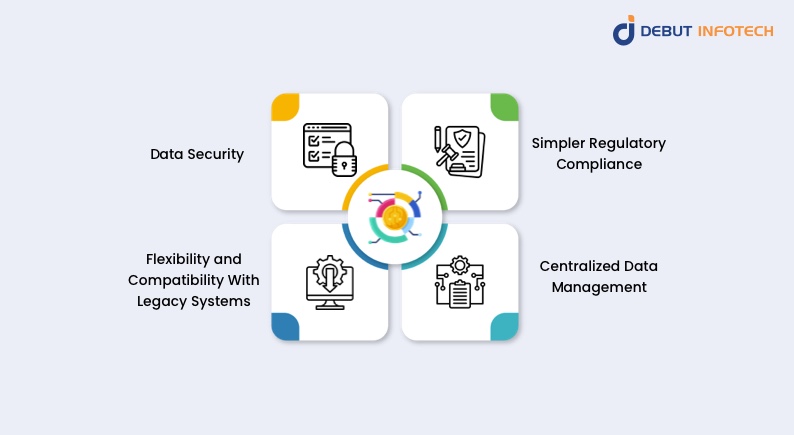
1. Data Security
This is the first and most obvious benefit of data tokenization. By converting vital information into tokens and securely storing personally identifiable information in secure databases, data tokenization protects all kinds of data from theft, unauthorized access, or corruption throughout its entire life cycle.
This is highly relevant in several ways. First, it makes it increasingly difficult for malicious actors to gain access to this information. The tokens do not hold any intrinsic value, so they cannot be reverse-engineered to access the original data without the tokenization system.
Secondly, if a breach does occur, only the tokens—which aren’t valuable—can be accessed, thus significantly minimizing the effect of the breach.
2. Simpler Regulatory Compliance
Tokenization of data makes it much easier for organizations to comply with stringent regulatory compliance requirements, especially in highly regulated industries like healthcare and financial services. The technique reduces the total amount of contact an organization has with sensitive information, thus reducing its compliance scope with regulations like GDPR and PCI DSS.
3. Flexibility and Compatibility With Legacy Systems
It is relatively easy to use data tokenization with existing systems. Be it vendors, internal departments, or other third-party systems, tokens have the flexibility to conform to the specific formats required by most legacy applications. As such, businesses do not need to make significant system adjustments to accommodate their application.
This is a good thing because it means they don’t have to spend more on additional system updates or the acquisition of compliant systems.
4. Centralized Data Management
Owing to the need for a token database and token maps, data tokenization allows organizations to manage all their data in one place. The same applies to all data access policies and protocols—they can all be managed from a single point.
Centralization is a huge plus to an organization’s data management infrastructure because it grants better control over all internal data and third-party data-sharing procedures. It requires creating robust data access security policies and authorization procedures. As such, every time the original data needs to be accessed, the requesting entities must meet the requirements of these policies.
What’s more?
You get to update the policies at chosen intervals in order to keep things flexible and more secure. It’s safe to say data tokenization contributes to a healthy data storage and processing infrastructure.
While all these benefits are crucial to a system’s integrity, data tokenization isn’t the only cybersecurity technique capable of delivering them. Other common techniques, like data masking and encryption, can also be associated with some of these benefits. As such, many people often wrongly interchange these terms. Yet, there are subtle differences between them.
Let’s examine some of these differences below.
Data Tokenization vs. Data Masking
Both data tokenization and data masking are significant cybersecurity techniques for protecting sensitive data. Nonetheless, they both have different purposes and characteristics.
On the one hand, data tokenization replaces sensitive data with random alphanumeric strings or tokens while maintaining a clear link to the original data. On the other hand, data masking does a similar thing by replacing sensitive data with fictitious, non-sensitive substitutes without the use of a mapping table, as in data tokenization.
While data tokenization is reversible as long as an authorized user has access to the mapping table, data masking is only reversible with the use of a decryption procedure. Finally, data masking is often applied for testing, development, or reporting purposes.
Data Tokenization vs Encryption
Encryption is another security method often confused with data tokenization. It involves encoding data into an unreadable cyphertext using sophisticated cryptographic techniques and algorithms.
Unlike data tokenization, which simply replaces sensitive data with non-sensitive strings, data encryption converts the same data into an unreadable format. As such, encrypted data can be restored to its original using an encryption key. This contrasts starkly with the tokens generated by data tokenization, which have no inherent value of their own and can’t be restored to the original data using an encryption key. They can only be restored using the tokenization system and token map.
Furthermore, while tokens are generated randomly in data tokenization, the encrypted data generated by data encryption remains in its original form.
Enhance your Data Security with Comprehensive AI Development Services
Businesses across all sectors are avoiding data breaches using AI. Leverage our AI consulting services for your business’ iron-clad security.
Conclusion
With data tokenization, organizations can be assured that all of their sensitive data is out of the reach of unauthorized entities.
Once an organization identifies and categorizes the data to be tokenized, the tokenization system randomly substitutes it with tokens and maps it to the original data. It then securely stores the original data in a digital vault for future retrieval and usage.
The same procedures apply whether it’s for payment processing or handling personally identifiable information. So, even if a data breach is successful, the tokenization system minimizes the potential impact by ensuring that the tokens can not be used to retrieve the original data.
This is how data tokenization helps organizations maintain a more secure data infrastructure.
Frequently Asked Questions
Q. Is tokenization data masking?
While data tokenization and data masking are both relevant cybersecurity techniques for protecting sensitive information, tokenization is slightly different from data masking. Furthermore, tokenization is a type of data masking. Tokenization means replacing important customer information with randomly generated alphanumeric tokens, while data masking means replacing sensitive information that is currently in use with fictitious data.
Q. What is meant by tokenization of data?
Data tokenization means substituting vital data, such as customer information, with non-sensitive information that cannot be reverse-engineered to produce the original data. It is used to safeguard details like credit card numbers, social security numbers (SSN), and personally identifiable information (PII) like name, email address, phone number, and medical records.
Q. What is an example of tokenized data?
Let’s assume you make a purchase using a point-of-sale (POS) terminal. Your credit card number, which could be something like “12345678901,” is then replaced with a random alphanumeric string such as “f4Qe39yiOJj.”The token, in this instance, is an example of tokenized data.
Q. What is the difference between tokenization and hashing?
Hashing is a data protection technique used to transform sensitive data into a fixed-length string of characters called a hash through an irreversible process that helps verify the data’s integrity. On the other hand, tokenization is the process of replacing sensitive data with unique tokens with no intrinsic value
Q. What are the benefits of data tokenization?
Data tokenization benefits organizations and individual users by enhancing data security, simplifying regulatory compliance, maintaining flexibility and compatibility with legacy systems, and finally, ensuring centralized data management.
Talk With Our Expert
Our Latest Insights




USA
Debut Infotech Global Services LLC
2102 Linden LN, Palatine, IL 60067
+1-703-537-5009
[email protected]
UK
Debut Infotech Pvt Ltd
7 Pound Close, Yarnton, Oxfordshire, OX51QG
+44-770-304-0079
[email protected]
Canada
Debut Infotech Pvt Ltd
326 Parkvale Drive, Kitchener, ON N2R1Y7
+1-703-537-5009
[email protected]
INDIA
Debut Infotech Pvt Ltd
C-204, Ground floor, Industrial Area Phase 8B, Mohali, PB 160055
9888402396
[email protected]
Copyright © 2025, Debut Infotech. All rights reserved. | Privacy Policy
Leave a Comment