Table of Contents
Our Global Presence :
Home / Blog / AI/ML
Understanding Embeddings in Machine Learning: Why They Matter
by
April 10, 2025

by
April 10, 2025
The power of machine learning exists in its ability to transform the way we live and work. To utilize this powerful tool, it is important to know that the success of any machine learning model relies heavily on the quality of the training data used during its development. The creation of dependable and accurate machine learning outcomes depends fundamentally on high-quality training data.
The use of embeddings in machine learning allows models to capture complex patterns in data, leading to more accurate predictions. For organizations aiming to scale these efforts, partnering with experts offering Generative AI Integration Services ensures seamless implementation and optimization of embedding-based solutions.
In this blog post, we’ll explore why high-quality training data is vital for machine learning and how AI embeddings can enhance its effectiveness. We’ll dive into:
- The significance of high-quality training data
- Enhancing training data quality through AI embedding techniques
- Embedding use cases in real-world scenarios
- Guidelines for optimizing the use of AI embeddings
Let’s jump in!
Why is High-Quality Training Data Important?
Machine learning models can only achieve reliable results because high-quality training data directly impacts their accuracy. The effectiveness of model learning patterns and its delivery of reliable predictions depends on its training on large volumes of diverse, accurate, and unbiased data whether using single architectures or ensemble models in machine learning. If the training data is of poor quality or includes errors and biases, the model is likely to generate inaccurate and possibly biased predictions.
The quality of training datasets remains essential for all model types such as generative AI models (e.g., ChatGPT and Meta’s LLaMA). The Stanford Foundation Model Transparency Index (2024) indicates that users must access clear information about data sources to examine how models operate and their reliability and fairness levels and performance metrics. Most leading foundation models in the market fail to provide sufficient visibility into their training data which proves why both data quantity and quality remain critical to build strong advanced language models.
In domains like image recognition, a model’s predictive accuracy is similarly dependent on high-quality training data. If the training set contains mislabeled or incomplete images, the model may struggle to correctly identify or classify visuals.
Similarly, when training data contains specific group or demographic biases the model may replicate these biases that create unfair results for those outside the specific groups. For example, Amazon’s AI recruitment tool demonstrated gender bias because it used male-biased historical data during its training phase.
Therefore, ensuring high-quality training data is critical for building robust and equitable machine learning models. This requires sourcing diverse and representative data and applying meticulous preprocessing, cleaning, and accurate labeling practices before training.
Why Do Embeddings Turn Raw Data into Gold?
Discover how embeddings unlock hidden patterns, capture context, and supercharge your ML models. From text to trends, we’ll show you frameworks to transform chaos into clarity. Master the magic behind the models—no PhD required.
What is an Embedding in Machine Learning?
In machine learning, the embedding function is used to transform data points into lower dimensional spaces that retain their core relationships and patterns. Complex data types such as images, text (often preprocessed via tokenization in machine learning) and audio benefit from embedding techniques in a way that facilitates better algorithmic processing.
Embeddings set themselves apart from other machine learning methods by being learned through training a model on a vast dataset, rather than being directly defined by a human expert. This enables the model to understand complex patterns and relationships within the data that might be difficult or even impossible for a human to recognize.
The learned embeddings serve as foundational inputs for other machine learning models, such as classifiers or regressors or even generative adversarial networks. This allows the model to make predictions or decisions by recognizing the fundamental patterns and relationships in the data, instead of relying solely on unprocessed data.
There are various types of embeddings that can be utilized in machine learning. Some of which include:
Image Embeddings
Image embeddings transform images into a lower-dimensional space which maintains essential visual characteristics including color and texture. Through this transformation, machine learning models perform tasks such as image classification, object detection, and various other computer vision tasks.
Word Embeddings
Word embeddings enable machines to visualize words as vectors in low dimensional structures. They create vector-based language representations, often built upon foundational steps like tokenization in machine learning, which help machine learning models process information better and natural language.
Graph Embeddings
Graph embeddings represent graphs, which are networks of interconnected nodes, as vectors in a lower-dimensional space. These embeddings capture the relationships between nodes, enabling machine learning models to perform tasks such as node classification and link prediction.
Embeddings compress data fundamental elements into lower-dimensional space, to enable efficient computation and discovery of complex patterns and relationships that might not be otherwise apparent. These advantages facilitate a variety of AI embedding applications, as detailed below, and underscore their pivotal role in shaping the future of AI, where efficient data representation drives innovation across domains.
Applications of Embeddings
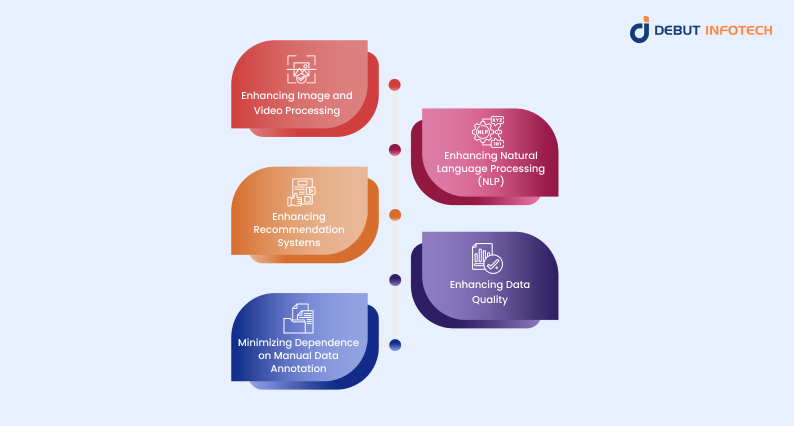
AI embeddings are widely used in data creation and machine learning, with several key applications, including:
1. Enhancing Image and Video Processing
Image and video embeddings play a crucial role in object detection, recognition, and classification. By converting images and videos into vector representations, machine learning algorithms can more easily identify and categorize various objects within them.
2. Enhancing Natural Language Processing (NLP)
Word embeddings serve as an indispensable component for performing Natural Language Processing operations including sentiment analysis, language translation, and chatbot development. These techniques also align with generative AI trends, where vector representations enable advanced text generation and contextual understanding
3. Enhancing Recommendation Systems
The recommendation system of collaborative filtering uses embeddings for users and items to create tailored suggestions. By integrating ensemble models in machine learning, these systems can combine multiple algorithms (e.g., matrix factorization and neural networks) to improve recommendation accuracy and robustness.
4. Enhancing Data Quality
AI embeddings enable the improvement of data quality through their ability to eliminate anomalies while discovering hidden semantic relationships. The process becomes extremely useful because it works well with datasets that contain unstructured or incomplete information. Through word embeddings in machine learning, the system connects semantically similar words which results in better context understanding and higher application performance.
5. Minimizing Dependence on Manual Data Annotation
Programs that employ AI embeddings can execute automatic data labeling operations without human intervention.
AI embeddings function to perform automatic data labeling by referring to embedding representations. AI embeddings reduce the need for labor-intensive data labeling processes which maximizes efficiency with substantial data sets.
AI embeddings enable a wide range of applications, including those built with generative AI frameworks, that deliver important advantages for better data quality and automatic data labeling removal from human involvement. Now, let’s explore how this can be of advantage when using AI embeddings to generate high-quality training data.
Advantages of Using Embeddings in Data Generation
Below are some key benefits of leveraging embeddings during the data creation process:
1. Minimize Bias
Using AI embeddings in training data brings deeper insight into data patterns which helps minimize bias identification. Detecting possible bias sources through this approach makes it possible to resolve bias issues in datasets that train machine learning models for better representation. As a result, the models generate predictions with more accuracy and fairness through this approach.
2. Enhance Model Effectiveness
AI embeddings enable several benefits such as improved efficiency, better generalization, and better overall performance across various machine learning tasks. These models reduce computational time and enable the detection of complex patterns through minimization of overfitting, while ensemble models in machine learning further amplify these advantages by combining multiple models to improve robustness and accuracy.
By preparing systems to recognize unknown data patterns, embeddings also support adaptive AI development, where models dynamically adjust to evolving data inputs. This synergy ensures machine learning solutions remain scalable, efficient, and effective in real-world applications.
3. Build a Bigger and More Diverse Dataset
Dataset completion benefits from embeddings because these methods automatically identify relationships between data points to detect and rectify human labeling errors. Embeddings use data patterns they have learned during training to handle missed information.
AI models use surrounding data representations to calculate missing values which enhances accurate and dependable data analysis. This approach contributes to improved machine learning model performance by offering more complete and representative data for training.
How to Generate High-Quality Training Data with Embeddings
The majority of machine learning algorithms need numerical input data, requiring a conversion process of all data into numbers. The transformation of information requires generating numerical format by converting text to bag-of-words structure and transforming image data to pixel arrays or rearranging graph data into numeric matrices.
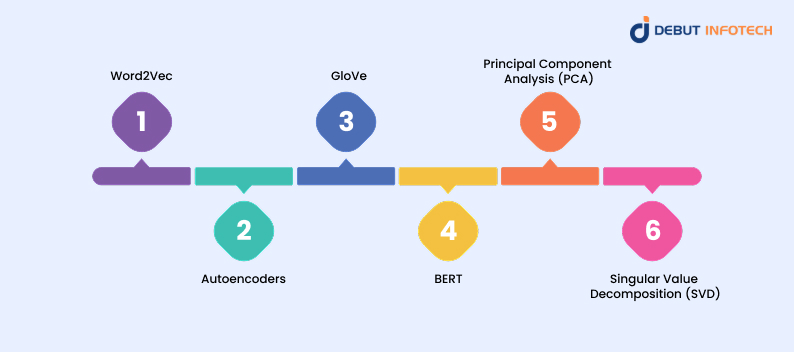
After converting the data into a numerical format, you can use machine learning methods to embed it. The data transformation process covers the conversion of high-dimensional information to lower-dimensional forms while maintaining semantic content, a cornerstone concept in embeddings in machine learning. Here are a few commonly used embedding techniques:
Word2Vec
Word2Vec stands as a recognized method for producing word embeddings that represent words as vectors in a high-dimensional space. It is a process that trains a neural network through large text data to identify what words come before and after specific words. The resulting embeddings reflect semantic and syntactic relationships between words, such as similarity and analogy.
Word2Vec is useful for a range of natural language processing tasks, including language translation, text classification, and sentiment analysis. These techniques also complement advancements in text to speech models, where semantic understanding of language is critical for generating natural-sounding audio outputs. Additionally, it finds applications in recommendation systems and image analysis.
Word2Vec can be implemented using two primary approaches, the Continuous Bag-of-Words (CBOW) model and the Skip-gram model. In CBOW, the model predicts a target word based on its surrounding context, whereas in Skip-gram, it predicts the context from a given target word. Each model has its strengths and weaknesses, and the decision to use one over the other depends on the particular application and data characteristics.
Autoencoders
Autoencoders are neural network architectures used in unsupervised learning. They feature an encoder network that compresses the input data into a lower-dimensional form (encoding) and a decoder network that reconstructs the original data from this encoding. The objective of an autoencoder is to discover a compressed, yet informative representation of the input, highlighting its most important features.
Autoencoders include an encoder neural network that compresses input data into a lower-dimensional representation or embedding. The decoder network then reconstructs the original data from this embedding. When trained on a dataset, the encoder learns to extract important features and compress the input data into a compact form. These embeddings in machine learning can be applied in downstream tasks like clustering, visualization, or transfer learning.
GloVe
The Global Vectors for Word Representation system known as GloVe serves as a method for representing words as vectors. Similar to Word2Vec, GloVe is a neural network-based approach. However, while Word2Vec relies on a shallow neural network, GloVe uses a global matrix factorization technique to learn word embeddings.
GloVe generates a co-occurrence matrix through the process of counting pairs of words in their mutual context occurrences. The rows of the matrix represent the words, while the columns correspond to the contexts in which these words occur. The matrix applies factorization to split into two independent matrices that represent words and contexts. The mathematical combination of the two matrices produces the final word vector output.
BERT
BERT (Bidirectional Encoder Representations from Transformers) is a well-known language model developed by Google and used in a range of natural language processing (NLP) tasks, including word embedding. It is a deep learning model built on a transformer architecture that creates word embeddings by considering the surrounding context of words. This gives BERT the ability to capture both the meaning of individual words and the relationships between them in a sentence.
BERT establishes word embeddings from extensive textual training which makes it an effective solution for developing quality word representations. The embeddings generated from BERT prove effective in various tasks including sentiment analysis together with text classification and question-answering. BERT enables specific task adjustment to enhance its performance on particular problems.
BERT is a strong tool for creating high-quality word embeddings that can be applied to many NLP tasks, including those developed by generative AI development companies. One downside is that it can be resource-heavy, needing a lot of power for training and use. However, pre-trained BERT models can be fine-tuned for specific tasks, which
helps lower the cost of training.
Principal Component Analysis (PCA)
Principal Component Analysis (PCA) takes original data through a process that generates uncorrelated features known as principal components. The method selects important information from data samples by removing unessential information.
PCA embedding starts by transforming the data into a mean-zero value configuration with unit variance before proceeding with the analysis. The adjusted data receives a subsequent calculation of covariance matrix. The covariance matrix eigenvector and eigenvalue calculation takes place afterward followed by an eigenvector sorting process based on descending eigenvalue values. The new feature space is formed from top k eigenvectors which determines the number of dimensions needed in the embedded space.
Finally, the original data is transformed into a new feature space using the chosen eigenvectors to create the embedded representation. PCA is a popular method for embedding, especially for image and audio data, and is commonly used in applications like facial and speech recognition.
Singular Value Decomposition (SVD)
Singular Value Decomposition (SVD) is part of PCA, so we’ll explain it briefly. SVD analyzes matrices so they become U, Σ, and V parts containing left singular vectors and singular values, and right singular vectors respectively.
Singular values together with vectors extract major data points from matrix structures to perform dimensionality reduction for embedding generation. SVD functions as a data reduction technique to create embeddings from diverse datasets that include text, images and graphs just like PCA.
The SVD algorithm finds applications in recommendation systems and both text and image processing. SVD functions as an effective technique to produce high-quality embeddings that enhance machine learning models’ operational efficiency.
Best Practices for Embeddings in Computer Vision & Machine Learning
Here are some key tips to ensure the AI embeddings you create for training data are of high quality:
Selecting the Right Embedding Method
Selecting the right embedding technique is important for creating quality training data with AI embeddings.
Different techniques work better for different types of data and tasks. It’s important to think about the data and tasks before choosing a technique. Also, consider the computational resources needed and the size of the embeddings.
It’s also important to keep up with the latest research and methods in AI embeddings. This helps ensure the use of the best and most efficient techniques for creating high-quality training data.
Tackling Data Bias and Promoting Data Diversity
To avoid bias in embeddings, it’s important to use a large and diverse dataset during training. This ensures the embeddings reflect the full range of data variations, leading to more accurate results. For specialized guidance on balancing diversity and mitigating bias, collaborating with generative AI consultants can provide tailored strategies to refine datasets and improve embedding fairness.
Validating the Embeddings
It’s important to check the quality of the embeddings to make sure they capture the right information and work well for the task. Techniques like model combination schemes in machine learning can cross-verify embedding robustness across different architectures. Visualizing the embeddings in a simpler, lower-dimensional space can help spot patterns or groups in the data, which makes the validation process easier.
Future Directions
Future improvements in embedding techniques will greatly increase their accuracy and efficiency. New methods are constantly being created to better understand complex meanings and context.
Techniques like ELMo, BERT, and GPT-3 have greatly advanced this field by offering a better understanding of context and more accurate language representations. These improvements help AI applications perform better and understand human language more effectively.
Their connection with generative AI models, particularly those developed by generative AI development companies, is set to greatly improve AI applications. This combination helps these models better understand context and produce text that is more relevant and coherent.
For example, models like T5 help generate accurate summaries, making them useful for applications like automatic report generation, news summarization, and virtual assistants.
As these technologies keep improving, they are expected to provide better AI solutions that can work with different types of data, like text, images, and audio, resulting in more useful and insightful applications.
Stuck in the Data Noise? Let’s Find Your Signal.
Talk with our ML architects at our machine learning development company to design embeddings that actually align with your goals. Whether it’s NLP, recommendation engines, or custom models, we’ll help you decode the ‘why’ and ‘how.’ Ready for context that clicks?
How Debut Infotech Can Help With Embedding in Machine Learning
At Debut Infotech, a leading machine learning development company, we specialize in providing advanced technology solutions for embedding in machine learning to help businesses improve their AI models and data strategies. Our team of experts creates efficient, high-quality embedding models tailored to your specific needs, whether for natural language processing (NLP), computer vision, or other AI applications.
At Debut Infotech, we use our expertise in vector spaces, feature embeddings, and dimensionality reduction to create scalable solutions that help your models understand complex data patterns, boosting performance and accuracy.
We have experience working across various industries, from finance to healthcare, and specialize in integrating machine learning into embedded systems for faster and more reliable decision-making. Whether you want to build embedding layers for your AI model or improve your existing machine learning algorithms, Debut Infotech’s full support will help keep your business ahead in the competitive AI field. Looking to hire generative AI developers? Contact us today to see how we can help enhance your machine-learning efforts.
Frequently Asked Questions (FAQs)
Q. What are embeddings in machine learning (simplified)
Embeddings are a way to turn complex data, like words or images, into simpler numbers that a machine learning model can understand. They help the model find patterns and relationships in the data by reducing its size while keeping important meaning. This makes it easier and faster for the model to learn and make accurate predictions.
Q. How does feature embedding improve machine learning models?
Feature embedding helps machine learning models work better by turning complex data into simpler, smaller representations that keep the most important information. This makes it easier for the model to focus on useful patterns without being distracted by extra or irrelevant details. As a result, the model can make faster and more accurate predictions, especially in tasks like image recognition and understanding language.
Q. Why are embeddings important in machine learning for embedded systems?
Embeddings are important in machine learning for embedded systems because they make models smaller and faster. They turn large, complex data into simpler forms, which helps the models run more efficiently on devices with limited power and memory. This allows embedded systems to handle tasks like real-time image recognition, voice assistants, and predictive maintenance in IoT devices.
Talk With Our Expert
Our Latest Insights




USA
Debut Infotech Global Services LLC
2102 Linden LN, Palatine, IL 60067
+1-703-537-5009
[email protected]
UK
Debut Infotech Pvt Ltd
7 Pound Close, Yarnton, Oxfordshire, OX51QG
+44-770-304-0079
[email protected]
Canada
Debut Infotech Pvt Ltd
326 Parkvale Drive, Kitchener, ON N2R1Y7
+1-703-537-5009
[email protected]
INDIA
Debut Infotech Pvt Ltd
C-204, Ground floor, Industrial Area Phase 8B, Mohali, PB 160055
9888402396
[email protected]
Copyright © 2025, Debut Infotech. All rights reserved. | Privacy Policy
Leave a Comment