Table of Contents
Home / Blog / Artificial Intelligence
The Impact of GANs on Synthetic Data Generation
by

January 8, 2025(Updated: January 20, 2026)

by
January 8, 2025(Updated: January 20, 2026)
Introduction:
The need for data access is constantly rising, particularly for data gathered with funds from the public. At the same time, data collectors are limiting access to data due to worries about the availability of sensitive information and the identity of the respondents who provided the data.
A convincing approach for enabling broad access to data for analysis while addressing privacy and confidentiality concerns is the use of synthetic data sets, which are created to mimic specific important characteristics present in the real data and enable the drawing of reliable statistical conclusions.
This blog’s objective is to evaluate different methods for creating and evaluating synthetic data sets, along with their limits, inferential justification, and potential future research areas.
Let’s dive in!
What is Synthetic data?
Non-human-generated data that replicates real-world information is called synthetic data. It is created using simulations and algorithms powered by generative AI technology. While lacking some of the details of the original data, synthetic data retains the same mathematical characteristics. Organizations leverage synthetic data for machine learning research, testing, and development of new products. Recent advancements in AI have accelerated synthetic data generation, making it increasingly significant in the context of data privacy regulations.
Unlock the potential of synthetic data.
Discover our tailored solutions for generating realistic and privacy-preserving synthetic datasets across various industries.
Synthetic data generation methods
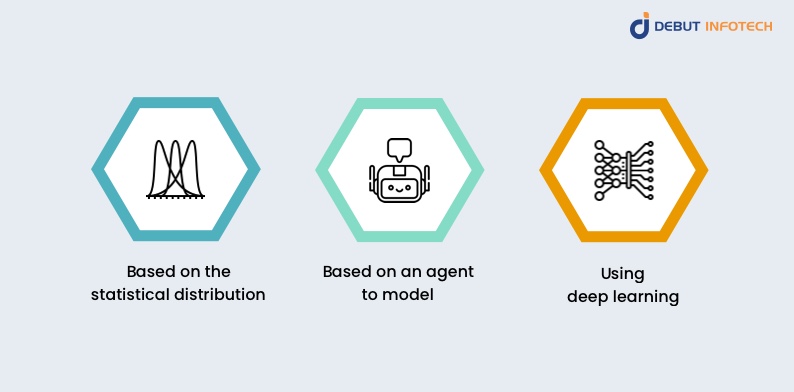
For building a synthetic data set, the following techniques are used:
Based on the statistical distribution
This method involves analyzing real data distributions to derive numbers that replicate the same statistical properties. You can use this approach when genuine data is unavailable. A data scientist with a strong understanding of the actual data’s statistical distribution can generate a random sample dataset. Common distributions used include normal, chi-squared, and exponential distributions. The accuracy of the trained model heavily relies on the data scientist’s expertise in this method.
Based on an agent to model
This approach allows you to develop an ai model that explains observed behavior and then use that model to generate random data. It involves fitting a model to the known data distribution. Businesses can leverage this technique to create synthetic data. Additionally, different machine learning techniques can be used to fit the distributions. However, decision trees can overfit when used for future predictions due to their simplicity and depth.
Using deep learning
Deep learning models that utilize Generative Adversarial Networks (GANs) or Variational Autoencoders (VAEs) are employed for creating synthetic data.
- Variational Autoencoders (VAEs): VAEs are a type of unsupervised machine learning model that uses encoders to compress real data and decoders to reconstruct a representation of the real data. The key justification for using VAEs is to keep the input and output data remarkably similar.
- Generative Adversarial Networks (GANs): GANs are two competing neural networks: a generator and a discriminator network. The generator network is responsible for creating synthetic data. The discriminator network functions by identifying fake data sets and notifying the generator about this distinction. The generator then modifies the next batch of data to improve its realism. Conversely, the discriminator refines its detection of fake data.
- Data Augmentation: It’s important to distinguish data augmentation from synthetic data generation. Data augmentation is a process where new data is added to an existing dataset, not creating entirely new data from scratch. Additionally, anonymizing data doesn’t create synthetic data.
The Evolution of Synthetic Data Generation Techniques
Synthetic data has a long history, dating back to the earliest forms of data collection methods used by ancient civilizations. Cuneiform writing and clay tablets were used to record information. The pace of data generation accelerated alongside technological advancements.
A turning point came with the invention of computers in the mid-20th century. This breakthrough revolutionized statistical analysis and paved the way for modern data science. The combination of computer science, statistics, and mathematics laid the foundation for complex synthetic data synthesis.
The development of synthetic data production has been significantly bolstered by AI. First-generation methods relied on traditional statistical techniques like sampling and randomization. However, sophisticated machine learning algorithms are now incorporated into second-generation techniques, including Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs).
Today, synthetic data production encompasses a wide range of data types. In addition to tabular data for e-commerce and healthcare, it also includes non-tabular media like text, images, and audio. These methods are transforming data-driven operations across various industries.
What are Generative Adversarial Networks (GANs)?
One type of machine learning framework is a generative adversarial network. A GAN learns to produce new data with the same statistics as the training data set based on the training data set. Any type of data, including text, photos, and videos, can be produced by the GAN.
The discriminator and generator play a game to determine how GANs operate. An image or other fake sample is produced by the generator using a random vector as input. The discriminator outputs a probability of being real after receiving as inputs a real or a false sample. The discriminator’s objective is to accurately identify the samples, while the generator’s objective is to deceive the discriminator. Both models are trained concurrently, and the procedure ends when they achieve a state of balance where the discriminator is unable to distinguish between authentic and fraudulent samples.
Innovation in synthetic data has been revolutionised by GANs. The Generator and the Discriminator are their two main parts. While the discriminator separates authentic samples from fraudulent ones, the Generator synthesises data. Through constant competition, this pair improves each other’s performance.
As it develops, the Generator generates data that is more realistic. It starts with random noise and adjusts its output according to the feedback from the discriminator. On the other hand, the discriminator learns to spot phoney data. The result of this unrelenting struggle is artificial data that closely resembles real-world data.
GANs are used in a variety of industries, including banking and healthcare. They provide high-quality synthetic data that is comparable to information that is ready for production. The hazards involved in managing private customer information are decreased by this innovation. The time-to-market for new data production projects has been greatly shortened using GANs.
Training GANs can be difficult, they need patience and a dataset that closely resembles actual data. The effectiveness of the discriminator has a significant impact on the Generator’s performance. Notwithstanding these challenges, GANs have shown great promise in natural language processing, computer vision, and medical imaging.
Here at Debut Infotech, we go beyond just building GAN models. We believe in a future where misinformation can be limited; together we can implement safeguards against malicious uses of synthetic data, like deepfakes.
Revolutionize Your Data Strategy with GANs
We create high-quality synthetic data using GANs that enhances AI model training and innovation. Ready to transform your approach?
Synthetic data generation and labelling
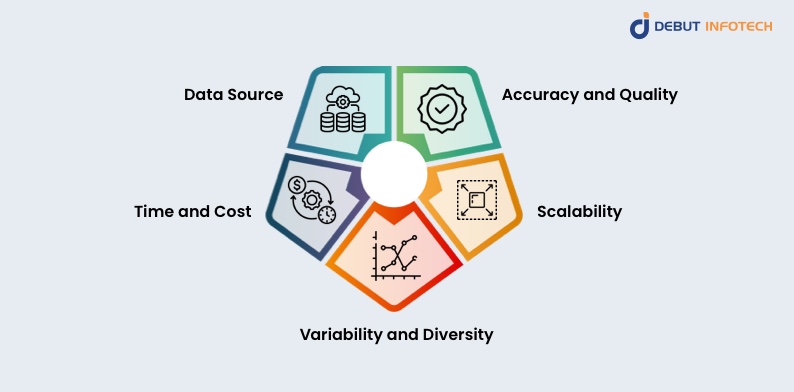
Synthetic data and human-generated labels have different functions in AI model training, and they vary in a number of important ways:
1. Data Source
Human-Generated Labels:
These are annotations made by people, frequently using their knowledge, skills, or experiences. They entail locating, categorising, or labelling data points (text, photos, etc.).
Synthetic data:
Synthetic data is data that has been produced artificially using simulations or algorithms. It is intended to replicate actual data distributions rather than being based on observations from the real world.
2. Accuracy and Quality
Human-Generated Labels:
The proficiency and reliability of the annotator can affect the quality. The labelling process may also be influenced by human subjectivity and bias, which could result in inaccurate results.
Synthetic Data:
Because it is produced under controlled conditions, it can be of high quality and consistency, but its applicability and realism vary depending on the underlying model or algorithm. It might not faithfully depict real-world situations if it is poorly developed.
3. Time and Cost
Human-Generated Labels:
Manually labelling data, especially for big datasets, can be expensive and time-consuming. It frequently calls for substantial human resources.
Synthetic Data:
With the right models in place, creating synthetic data can be quicker and less expensive. It can generate vast amounts of data quickly, which is especially useful when training intricate models.
4. Scalability
Human-Generated Labels:
Labelling projects can be difficult to scale since they need more human resources, which can result in longer turnaround times and greater expenses.
Synthetic Data:
It is perfect for training big AI models since it can be readily scaled up to produce as much data as required without being constrained by human availability.
5. Variability and Diversity
Human-Generated Labels:
The accessible data and the annotators’ prejudices may restrict the range of labelled data. It might not record uncommon occurrences or all edge cases.
Synthetic Data:
To improve model robustness, it can be made to incorporate a variety of scenarios, edge situations, or uncommon occurrences that might not be adequately represented in real data.
Industries Gaining from Synthetic Data: Examining Uses in Different Fields
Synthetic data has become a valuable tool across various industries due to its diverse applications and advantages. In healthcare, researchers can conduct studies and develop new treatments without compromising patient privacy. It also helps improve diagnostic accuracy and train medical professionals. In finance, synthetic data helps companies test and refine their models and algorithms, ensuring stability and compliance. It also facilitates the development of personalized financial services and solutions. In transportation, synthetic data is particularly useful for testing and validating traffic management systems and autonomous vehicles, mitigating risks and enhancing safety.
Synthetic data is also used in marketing, retail, and cybersecurity, enabling companies to enhance data security, optimize marketing campaigns, and analyze consumer behavior. Overall, synthetic data presents significant opportunities for innovation and progress in a wide range of sectors.
Final Thoughts
The revolution of AI is significantly impacted by synthetic data. Given that 78% of companies are having trouble with data in AI, creating synthetic data is a crucial remedy. It’s about changing our approach to data creation, going beyond simple data augmentation.
Using synthetic data serves as a strategic tool, not just a passing fad. It increases the potential of AI, promotes progress, and protects privacy. The impact of synthetic data is clear; it’s changing the rules of the game, not simply changing the game itself. Synthetic data has a bright future thanks to continuous advances in AI.
We at Debut Infotech offer the best Generative AI development services and strongly believe that there’s a lot more AI can do in the generation of synthetic data. Our expert Generative AI developers are ready to ensure you don’t only stay up to date but also excel in developments.
Frequently Asked Questions (FAQs)
Q. Why is synthetic data important?
For businesses that handle sensitive or private data, synthetic data is invaluable. Its ability to mimic the traits and trends of actual data without disclosing private information contributes to data security while still enabling researchers, analysts, and decision-makers to obtain insightful knowledge.
Q. How is synthetic data created?
Non-human-generated data that replicates real-world data is called synthetic data. It is produced by calculating simulations and algorithms using generative AI technology.
Q. Can synthetic data replace real data?
No, synthetic data cannot fully replace real-world data; rather, it can be used to augment it.
Q. How to generate synthetic data for machine learning?
Advanced techniques like Generative adversarial networks, variational autoencoders (VAEs), and others can be employed to generate synthetic data.
Q. Can generative AI produce synthetic data?
Yes, generative artificial intelligence (AI) can produce synthetic data by using AI algorithm.
About the Author
Gurpreet Singh, co-founder and director at Debut Infotech, is a leader with deep expertise in AI and ML technologies. He collaborates closely with CXOs, business leaders, and IT teams to understand their strategic goals and operational challenges. By leveraging Design Thinking workshops, conducting user research, and mapping processes, he identifies pivotal opportunities for AI-driven transformation across the organization. His focus lies in prioritizing high-impact use cases and aligning them with the most suitable AI and ML technologies to deliver measurable, impactful business outcomes.
Talk With Our Expert
Our Latest Insights



Leave a Comment