Table of Contents
Home / Blog / Artificial Intelligence
The Basics of Supervised vs. Unsupervised Learning in ML Models
by

March 25, 2025(Updated: January 20, 2026)

by
March 25, 2025(Updated: January 20, 2026)
Grasping the fundamentals of supervised learning and unsupervised learning is essential for anyone entering the world of machine learning. These two approaches define how models process data and make predictions.
But how do machines actually learn from data, and what makes supervised vs unsupervised learning more suitable for specific tasks?
Supervised learning relies on labeled data, where algorithms like decision trees and support vector machines learn from predefined outputs. On the other hand, unsupervised learning works with unlabeled data, using clustering techniques and neural networks to identify hidden patterns. Without a solid understanding of these methods, building accurate and efficient models becomes challenging.
This article explores their differences, advantages, and real-world applications to help you navigate the field of machine learning with confidence.
What Is Supervised Learning?
Supervised learning is a fundamental machine learning technique where models are trained using labeled datasets to establish relationships between input features and known output labels. This technique plays a crucial role in AI supervised and unsupervised learning strategies, ensuring accurate predictions across different domains. The dataset used for training consists of structured input-output pairs, allowing the model to detect patterns and generalize to new, unseen data.
Types of Supervised Learning
Classification
Classification involves predicting distinct categories or class labels based on input data. The model learns to assign new data points to predefined groups by analyzing past examples. For instance, an email filtering system can classify messages as spam or legitimate based on sender details, content, and keywords.
Regression
Regression focuses on predicting continuous values by identifying relationships between variables. The model learns patterns from historical data to make numerical predictions. A common example is real estate pricing, where the model estimates house values based on features like square footage, number of bedrooms, and location.
Not Sure Where to Start Your AI Journey? Let’s Figure It Out Together
Supervised learning helps AI learn from the past, while unsupervised learning finds patterns you didn’t even know existed. Together, they can take your business to the next level. Ready to turn raw data into real results?
Evaluation of Supervised Learning Models
Regression
- Mean Absolute Error (MAE): Measures the average absolute difference between predicted and actual values. It provides an intuitive metric for understanding the typical magnitude of errors in a model’s predictions. A lower MAE indicates higher accuracy.
- Mean Squared Error (MSE): Computes the squared differences between predicted and actual values before averaging. By squaring the errors, MSE penalizes larger deviations more heavily, making it useful when significant errors need to be minimized.
- Root Mean Squared Error (RMSE): Takes the square root of the MSE, making it interpretable in the same units as the target variable. RMSE is particularly useful when larger errors are more impactful on decision-making.
- R-Squared (R²): Evaluates the proportion of variance in the target variable that is explained by the model. R² values range from 0 to 1, with higher values indicating better model fit.
- Mean Absolute Percentage Error (MAPE): Expresses prediction errors as a percentage of actual values. It helps in understanding model accuracy in relative terms, but it can be unstable when actual values are close to zero.
- Adjusted R-Squared: An improved version of R² that accounts for the number of predictors in the model. Unlike R², it penalizes adding unnecessary features, making it more useful for feature selection.
Classification
- Accuracy: Represents the fraction of correctly predicted instances over the total dataset. While widely used, it may not always be reliable, especially when dealing with imbalanced data.
- Precision: Measures the proportion of correctly identified positive cases out of all instances predicted as positive. It reflects the model’s ability to avoid false positives, making it crucial for tasks like spam detection.
- ROC-AUC (Receiver Operating Characteristic – Area Under Curve): Measures the model’s ability to distinguish between classes. A higher AUC indicates better performance.
- Log Loss (Logarithmic Loss): Evaluates how well a model predicts probabilities rather than just class labels. Lower values indicate better calibrated probabilities.
- Recall (Sensitivity): Calculates the fraction of actual positive cases correctly identified by the model. A high recall means the model successfully detects most positive instances, which is important in medical diagnoses and fraud detection.
- F1 Score: The harmonic mean of precision and recall, providing a balanced evaluation. It is particularly useful when a trade-off between precision and recall is necessary.
Real-Life Applications of Supervised Learning
1. Fraud Detection
Supervised learning is widely used in financial institutions to identify fraudulent transactions. By analyzing historical data with labeled instances of fraud and legitimate transactions, machine learning models can detect suspicious activities and prevent financial losses.
2. Medical Diagnosis
In healthcare, supervised learning helps in diagnosing diseases by analyzing patient records. Models trained on labeled medical data can classify symptoms and predict conditions such as cancer, diabetes, or heart disease, aiding doctors in early diagnosis and treatment planning.
3. Spam Detection
Email providers use supervised and unsupervised machine learning techniques to filter spam. By training models on labeled datasets containing spam and non-spam emails, the system can accurately classify incoming messages, ensuring users receive only relevant emails while blocking unwanted content.
4. Customer Churn Prediction
Businesses use supervised learning to predict customer churn by analyzing past customer behavior. By training models on labeled data indicating whether a customer stayed or left, companies can identify at-risk customers and take proactive measures to improve retention.
5. Speech Recognition
Supervised learning is essential in voice assistants like Siri and Google Assistant. By training models on labeled speech data, these systems can recognize spoken words, convert them into text, and execute commands accurately, improving user interaction and accessibility.
Advantages of Supervised Learning
1. High Predictive Performance
When trained on sufficient labeled data, supervised models achieve high accuracy in predicting outcomes, making them reliable for decision-making tasks.
2. Availability of Established Methods
Well-researched algorithms, such as decision trees, support vector machines, and neural networks, provide structured approaches for effective model training.
3. Effective Pattern Recognition
Supervised learning enables models to recognize intricate patterns and correlations in data, allowing them to make accurate predictions based on historical trends.
4. Defined Evaluation Metrics
Performance assessment is straightforward using established metrics like accuracy, precision, recall, and F1-score, ensuring objective.
5. High Predictive Performance
When trained on sufficient labeled data, supervised models achieve high accuracy in predicting outcomes, making them reliable for decision-making tasks.
Disadvantages of Supervised Learning
1. Risk of Overfitting
When a model memorizes patterns from the training data instead of learning generalizable insights, it may perform poorly on new inputs.
2. Time-Intensive Data Labeling
The process of manually labeling training data is resource-intensive, requiring significant time and effort to ensure accuracy.
3. Susceptibility to Data Bias
If the training dataset contains errors, imbalances, or biases, the model may inherit and reinforce these issues, leading to skewed predictions.
4. Limited Adaptability to New Data
Models trained on specific datasets may struggle to generalize effectively to unseen data, leading to reduced accuracy in real-world scenarios.
5. Dependence on Annotated Data
Supervised learning models require large volumes of labeled data, making the training process highly dependent on accurate annotations.
What Is Unsupervised Learning?
Unsupervised learning is a type of machine learning where algorithms analyze data to uncover patterns and structures without using labeled outputs. Unlike supervised learning, which requires predefined labels, this approach processes raw, unlabeled data to derive valuable insights.
These AI models autonomously detect relationships, group similar data points, and uncover hidden structures within datasets. By analyzing underlying distributions, unsupervised learning algorithms enable data-driven decision-making, making them valuable in tasks such as clustering, anomaly detection, and dimensionality reduction.
Types of Unsupervised Learning
Association
Association rule learning uncovers hidden relationships between variables in a dataset. It detects patterns in large datasets by analyzing how items are related, often used in market basket analysis and recommendation systems. A well-known example of unsupervised learning is the Apriori algorithm, which identifies frequent item sets and their associations.
Clustering
Clustering involves categorizing similar data points into groups based on shared characteristics, without predefined labels. This technique helps in identifying patterns within data by measuring similarities between points. Popular clustering algorithms include K-means, hierarchical clustering, and Gaussian Mixture Models (GMM), each offering different approaches to grouping data effectively.
Evaluation of Unsupervised Learning Models
Assessing the performance of unsupervised learning models is often more complex than evaluating supervised models, as there are no predefined labels to compare results against. However, various techniques exist to measure how well an unsupervised algorithm identifies patterns and structures within data.
Internal Evaluation Metrics
These metrics analyze the quality of clustering or grouping based on internal characteristics of the dataset rather than external references. Some commonly used metrics include:
- Cohesion and Separation Metrics: Cohesion evaluates the compactness of clusters by summing the distances of points within a cluster, while separation measures how distinct clusters are by analyzing the distance between cluster centroids.
- Inertia or Within-Cluster Sum of Squares (WCSS): Measures how compact clusters are by calculating the sum of squared distances between data points and their respective cluster centers.
- Dunn Index: Assesses the compactness and separation of clusters by comparing the smallest distance between clusters with the largest within-cluster distance. A higher value suggests well-separated and dense clusters.
External Evaluation Metrics
- Adjusted Rand Index (ARI): ARI evaluates clustering performance by comparing predicted clusters to true labels while adjusting for random chance. Higher ARI values indicate better clustering accuracy.
- Normalized Mutual Information (NMI): NMI measures the mutual dependence between predicted clusters and ground truth labels. It ranges from 0 to 1, where higher values indicate better alignment.
- Fowlkes-Mallows Index (FMI): FMI calculates the geometric mean of precision and recall to determine clustering accuracy. Higher values suggest better clustering performance.
- Cluster Accuracy (CA): Cluster Accuracy measures the percentage of correctly assigned labels by mapping clusters to ground truth classes. It helps understand how well clusters match real data groups.
Real-Life Applications of Unsupervised Learning
Unsupervised learning is widely used across different fields to analyze data, detect patterns, and group similar entities without predefined labels. Below are some key applications:
1. Customer Segmentation
Businesses leverage clustering techniques in unsupervised learning to categorize customers based on their purchasing behavior, demographics, and engagement levels. This enables companies to tailor marketing strategies, personalize recommendations, and optimize customer experiences.
2. Anomaly Detection
Unsupervised models play a crucial role in identifying unusual patterns in data. In cybersecurity, they help detect fraudulent transactions, network intrusions, and system anomalies by recognizing deviations from normal behavior.
3. Image and Video Analysis
Unsupervised learning is used in image recognition and video processing for tasks like face detection, object clustering, and content-based retrieval. These techniques enhance applications in security, medical imaging, and multimedia search engines.
4. Topic Modeling
Natural language processing (NLP) benefits from unsupervised learning to discover hidden themes in large text corpora. Algorithms like Latent Dirichlet Allocation (LDA) help categorize documents into topics, improving search engines, content recommendation, and automated text summarization.
5. Gene Expression Analysis
In bioinformatics, unsupervised learning aids in grouping genes with similar expression patterns, helping researchers understand genetic functions, disease markers, and drug discovery. These insights contribute to advancements in personalized medicine and genomics.
Advantages of Unsupervised Learning
1. Useful When Labeled Data Is Limited
In scenarios where acquiring labeled data is expensive or impractical, unsupervised learning provides a viable alternative for extracting valuable information.
2. Handling Large and Complex Datasets
This approach is particularly useful for analyzing vast amounts of unstructured data, enabling the discovery of meaningful insights without manual intervention.
3. Facilitates Data Exploration and Feature Engineering
By revealing intrinsic data structures, unsupervised learning assists in feature selection and engineering, improving downstream model performance.
4. Adaptability to Different Domains
Unsupervised learning methods are versatile and can be applied across various fields, including customer segmentation, anomaly detection, and natural language processing.
5. Identifying Hidden Structures
Unsupervised learning is effective in uncovering hidden patterns and relationships within data, even when no predefined labels are available.
Disadvantages of Unsupervised Learning
1. Vulnerability to Noisy Data and Outliers
Unsupervised learning is highly sensitive to anomalies, which can distort clustering or pattern recognition, leading to unreliable insights.
2. Absence of Standard Evaluation Metrics
Unlike supervised learning, unsupervised models lack well-defined benchmarks for assessing performance, making it challenging to measure accuracy.
3. Scalability Challenges
Handling large datasets with numerous features can increase computational complexity, making real-time processing difficult.
4. Complexity in Understanding Results
The patterns and structures detected by unsupervised algorithms can be difficult to interpret, requiring domain expertise for meaningful validation.
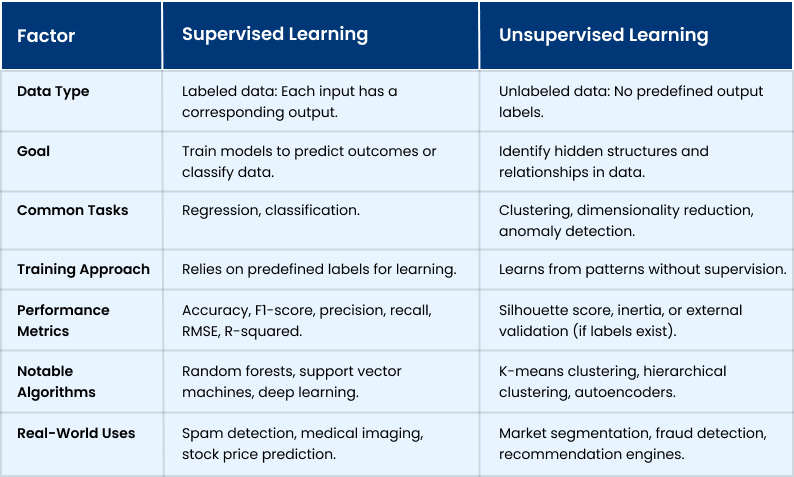
Difference Between Supervised and Unsupervised Learning
Don’t Let Your Data Go to Waste
Unsupervised learning drives 68% of customer segmentation success stories.
Whether you need precise predictions (supervised) or deeper insights (unsupervised), our ML experts tailor models to your goals. Missed opportunities cost more than innovation.
Final Thoughts
As machine learning continues to drive innovation across industries, businesses that harness the right techniques will maintain a competitive edge. Supervised learning provides accurate predictions using labeled datasets, while unsupervised learning uncovers hidden insights by detecting patterns within unstructured data. Choosing the right approach enhances decision-making, improves efficiency, and drives competitive advantage.
Successful AI adoption depends on a clear strategy. Companies leveraging machine learning can optimize operations, refine customer experiences, and unlock new growth opportunities. The right balance between supervised and unsupervised learning ensures smarter automation and data-driven innovation.
At Debut Infotech, we specialize in machine learning development services tailored to business needs. Our expertise spans from AI algorithms to advanced machine learning customer segmentation, ensuring impactful AI-driven solutions. From predictive modeling to advanced data clustering, we develop AI-powered solutions that align with your goals.
Let’s transform your data into actionable intelligence. Connect with us today!
Frequently Asked Questions (FAQs)
Q. Is facial recognition based on supervised or unsupervised learning?
A machine learning algorithm learns from examples or datasets provided during training. For instance, if you supply multiple images labeled as faces and non-faces, the algorithm will recognize patterns and accurately determine whether a given image contains a face. This approach, known as face detection, falls under supervised learning.
Q. How do training data and test data differ in supervised machine learning?
Training data is used to teach the machine-learning model, enabling it to recognize patterns and make accurate predictions. A larger training dataset generally enhances the model’s performance. Test data, on the other hand, is used to assess how well the model performs on unseen data, ensuring its accuracy and reliability in real-world applications.
Q. How is Supervised Learning Applied in Real Life?
Supervised Learning is widely used in real-world applications such as email spam filtering, stock market forecasting, and medical diagnostics, utilizing labeled data to enhance accuracy in predictions and classifications.
Q. Does Unsupervised Learning truly learn on its own?
Unsupervised Learning independently identifies patterns within data without relying on labeled examples, making it seem like self-directed learning. However, it depends entirely on data structures and distributions rather than predefined instructions.
About the Author
Gurpreet Singh, co-founder and director at Debut Infotech, is a leader with deep expertise in AI and ML technologies. He collaborates closely with CXOs, business leaders, and IT teams to understand their strategic goals and operational challenges. By leveraging Design Thinking workshops, conducting user research, and mapping processes, he identifies pivotal opportunities for AI-driven transformation across the organization. His focus lies in prioritizing high-impact use cases and aligning them with the most suitable AI and ML technologies to deliver measurable, impactful business outcomes.
Talk With Our Expert
Our Latest Insights



Leave a Comment