ON THIS PAGE
Progress0%





Our Global Presence :

What if your business could predict customer behavior, automate complex decisions, and uncover hidden patterns, all with minimal human intervention?
This is no longer a futuristic dream but a present-day reality, thanks to machine learning. Businesses worldwide are rapidly adopting AI-driven models to gain a competitive edge. In the United States alone, spending on artificial intelligence is projected to reach $120 billion by 2025, growing at a 26.0% compound annual growth rate (CAGR) from 2021 to 2025. Furthermore, 59% of organizations now view accelerated investments in AI and machine learning as a critical strategy for future-proofing their business.
But how do these businesses effectively train machine learning models to ensure accuracy, efficiency, and real-world applicability? In this guide, we’ll break down the essentials of ML model training, from selecting the right data to optimizing performance, so you can harness AI for smarter decision-making and sustained growth.
Model training is a fundamental stage in the machine learning lifecycle, where an algorithm learns patterns and relationships within data to make accurate predictions. During this process, the algorithm adjusts itself by optimizing weights, often measured through a loss function. The goal is to refine the model so that it generalizes well to new, unseen data.
Different types of learning approaches influence how model training is conducted. In supervised learning, the model is trained using labeled data, meaning it learns by mapping input features to known target values. This allows it to recognize patterns and make predictions based on past examples. In contrast, unsupervised learning involves training a model on unlabeled data, where it identifies inherent structures, clusters, or associations within the dataset without predefined outputs.
For businesses, effective ML model training translates to improved automation, enhanced decision-making, and more efficient operations. Whether optimizing marketing strategies, detecting fraud, or forecasting trends, well-trained ML models help organizations extract meaningful insights from their data.
Training a model is a crucial step in machine learning, as it transforms raw data into a functional model capable of making predictions and identifying patterns. A well-trained model ensures accuracy, reliability, and efficiency, making it a valuable asset for businesses looking to automate tasks, enhance decision-making, and gain insights from large datasets.
The effectiveness of training ML models depends on two key factors: the quality of data and the choice of algorithm. Training data must be diverse and representative to ensure the model performs well across different scenarios. Typically, data is divided into training, validation, and testing sets to fine-tune the model and evaluate its performance before deployment.
Selecting the right algorithm also plays a significant role. The best choice depends on the specific use case, whether it’s customer segmentation, fraud detection, or predictive analytics. Additional considerations include computational efficiency, model complexity, interpretability, and processing speed. Striking a balance between these factors is essential for achieving a model that is both powerful and practical in real-world applications.
Training a machine learning model is a structured process that transforms raw data into a tool capable of making accurate predictions. Businesses that leverage machine learning can automate decision-making, improve efficiency, and enhance customer experiences. However, a poorly trained model can lead to unreliable insights and flawed business strategies.
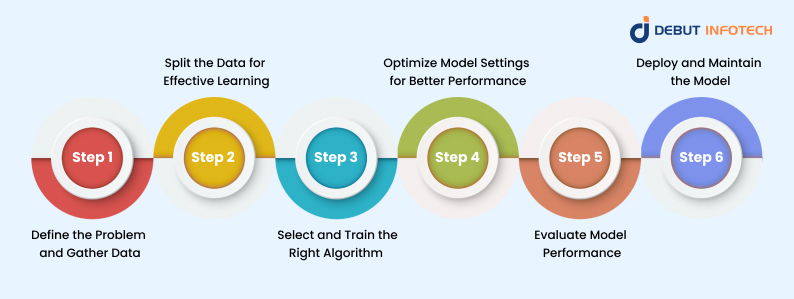
To ensure success, organizations must follow a systematic approach. Below is a detailed breakdown of how to properly train a machine learning model.
1. Define the Problem and Gather Data
Before training a model, it’s essential to clearly define the business problem it aims to solve. A well-defined objective guides data collection and model selection.
Key Steps:
Best Practices:
2. Split the Data for Effective Learning
To build a reliable model, the dataset must be divided into different subsets:
Cross-Validation for More Robust Models
A popular technique for data splitting is k-fold cross-validation:
Splitting data properly ensures the model generalizes well, rather than memorizing patterns, making it more reliable for real-world applications.
3. Select and Train the Right Algorithm
Choosing the right AI algorithms is crucial, as different machine learning techniques suit different tasks.
Common Algorithms and Use Cases:
Once an algorithm is chosen, training begins by adjusting model parameters to minimize errors and improve accuracy.
Training Strategies:
4. Optimize Model Settings for Better Performance
Fine-tuning a model involves adjusting certain configurations that influence how it learns using techniques recommended by AI development company experts. These settings impact accuracy, speed, and how well the model generalizes to unseen data.
Key Model Settings to Adjust:
Techniques for Finding the Best Settings:
Optimizing these settings ensures the model is neither too simple nor too complex, allowing it to make accurate predictions without overfitting.
5. Evaluate Model Performance
Once trained, the model must be tested using various performance metrics to determine how well it makes predictions.
Common Evaluation Metrics:
Real-World Validation
6. Deploy and Maintain the Model
Once the best-performing model is selected, it can be deployed into a live business environment. However, continuous monitoring is necessary to ensure it remains accurate and effective.
Key Deployment Considerations:
Ongoing Model Maintenance:
Training a machine learning model is not just about algorithms and data, it’s about transforming raw information into strategic business value. Well-trained models boost efficiency and innovation, from streamlining operations to improving customer experiences. However, achieving reliable results requires expertise, the right tools, and a structured approach to model development.
At Debut Infotech, a leading machine learning development services provider, we specialize in building intelligent, scalable, and business-driven AI solutions. Our team of experts ensures that every stage of model training from data preparation, algorithm selection, and performance optimization is tailored to your business needs. From AI integration to fine-tuning LLMs, we ensure your models align with the latest machine learning trends.
Other performance metrics, such as precision, recall, and F1-score, may also be used depending on the specific use case and the need for a more detailed evaluation.
A. Model training involves feeding an algorithm with structured data so it can recognize patterns and make predictions. This process refines the model’s ability to generalize from past examples. There are different types of learning approaches, with the most common being supervised and unsupervised learning.
A. A well-structured training process follows a cycle:
– The model makes an initial prediction.
– The error between the prediction and the actual result is measured.
– Adjustments are made to improve accuracy.
– This cycle repeats until the model reaches an optimal state.
A. Despite their power, ML models come with limitations, including:
– Data Quality & Quantity: Poor or insufficient data can reduce accuracy.
– Processing Time: Training complex models requires significant computational resources.
– Bias & Fairness: Incomplete or imbalanced data can lead to biased outcomes.
– Interpretability: Some advanced models operate as opaque systems, making understanding their decision-making process difficult.
A. – Step 1: Collect and preprocess data.
– Step 2: Split the dataset for training and evaluation.
– Step 3: Select and configure a model.
– Step 4: Train the model and assess performance.
– Step 5: Fine-tune and optimize the model.
– Step 6: Deploy the model and monitor its effectiveness.
A. The training process helps the model develop a mathematical representation of relationships within the data. Performance metrics, such as accuracy, measure how well the model understands these relationships, ensuring it can make reliable predictions when exposed to new data.
A. A training strategy defines the learning process of a model. It involves optimizing internal settings to minimize errors, ensuring that the model generalizes well to unseen data. Effective training strategies improve stability, accuracy, and efficiency.
A. Accuracy is determined by comparing the model’s predictions to actual outcomes. It is calculated by dividing the number of correct predictions by the total number of predictions made.
Our Latest Insights
USA
2501 Chatham, Rd Suite R Springfield, IL 62704
+1-708-515-4004
info@debutinfotech.com
UK
7 Pound Close, Yarnton, Oxfordshire, OX51QG
+44-770-304-0079
info@debutinfotech.com
Canada
326 Parkvale Drive, Kitchener, ON N2R1Y7
+1-708-515-4004
info@debutinfotech.com
INDIA
Sector 101-A, Plot No: I-42, IT City Rd, JLPL Industrial Area, Mohali, PB 140306
9888402396
info@debutinfotech.com


